- 图解vllm-原理与架构
- 图解vllm-推理服务与引擎
- 图解vllm-调度器与Block分配
- 图解vllm-执行器与worker
- 图解vllm-model之model和attention_backend
上文介绍了vLLM的分层架构,本节开始介绍vLLM的入口使用开发和引擎的详细设计。引擎层对使用者而言是承上启下的模块,在这一层不仅会对输入的参数、数据进行简单的处理封装,还会初始化核心模块,将源源不断的request组织起来,驱动迭代,最终返回给用户。
1. 引擎图解
引擎部分主要分为两部分:
- 入口: 主要分为同步和异步接口,会对输入的配置和数据进行转换成引擎args对引擎进行初始化。
- 引擎: 这个是顶层调度的核心模块,衔接scheduler和executor等下游核心模块。
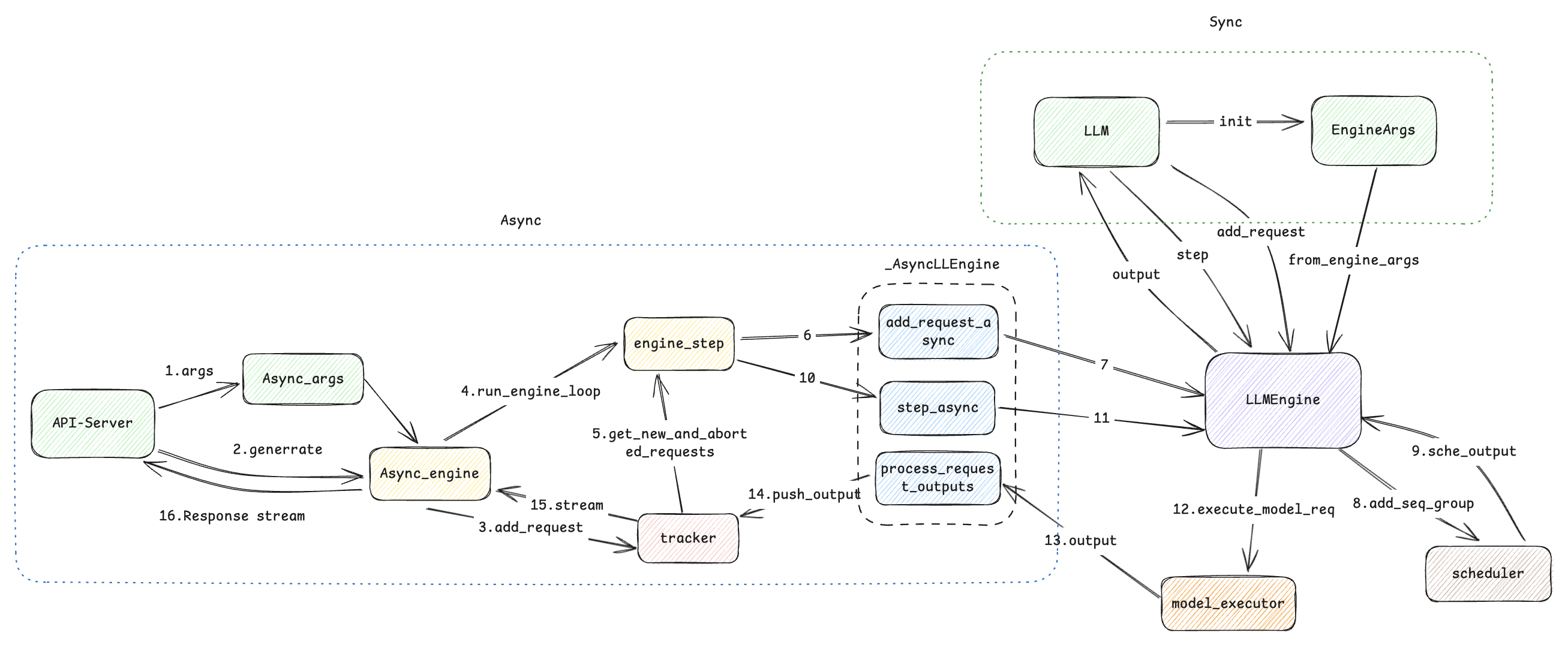
2. Endpoint
2.1 API-Server
API-Server是用来对网络服务暴露的入口,主要使用了asyncio库进行了协程封装,提高了服务的并发处理能力。
-
将服务端的启动args使用create_engine_config方法转换为EngineConfig,然后通过AsyncLLMEngine.from_engine_args方法创建出带有异步接口的引擎类AsyncLLMEngine(LLMEngine)。EngineConfig包含DeviceConfig、ModelConfig、CacheConfig、ParallelConfig、SchdulerConfig。对应的代码如下:
def create_engine_config(self) -> EngineConfig: # 硬件设备配置,包括cuda、neuron、openvino、tpu、cpu、xpu等设备 device_config = DeviceConfig(device=self.device) # ModelConfig包括了对model和tokenizer的定义, # dtype和随机数seed以及是否用pretrained weights还是dummy weights等 model_config = self.create_model_config() # 多模型和前缀缓存互斥 if model_config.is_multimodal_model: if self.enable_prefix_caching: logger.warning( "--enable-prefix-caching is currently not " "supported for multimodal models and has been disabled.") self.enable_prefix_caching = False # CacheConfig包括block_size(每个block多大), gpu_memory_utilization(GPU利用率水位)和 # swap_space(swap 的空间大小)。默认block_size=16,swap_space=4GiB cache_config = CacheConfig( block_size=self.block_size if self.device != "neuron" else self.max_model_len, # neuron needs block_size = max_model_len gpu_memory_utilization=self.gpu_memory_utilization, swap_space=self.swap_space, cache_dtype=self.kv_cache_dtype, num_gpu_blocks_override=self.num_gpu_blocks_override, sliding_window=model_config.get_sliding_window(), enable_prefix_caching=self.enable_prefix_caching, cpu_offload_gb=self.cpu_offload_gb, ) # 包括了tensor_parallel_size和pipeline_parallel_size, # 即张量并行和流水线并行的size,如果我们是单卡,那么这两个都是1 parallel_config = ParallelConfig( pipeline_parallel_size=self.pipeline_parallel_size, tensor_parallel_size=self.tensor_parallel_size, worker_use_ray=self.worker_use_ray, max_parallel_loading_workers=self.max_parallel_loading_workers, disable_custom_all_reduce=self.disable_custom_all_reduce, tokenizer_pool_config=TokenizerPoolConfig.create_config( self.tokenizer_pool_size, self.tokenizer_pool_type, self.tokenizer_pool_extra_config, ), ray_workers_use_nsight=self.ray_workers_use_nsight, distributed_executor_backend=self.distributed_executor_backend) max_model_len = model_config.max_model_len # 上下文长度如果大于32K,为了避免OOM开启分块预填充 use_long_context = max_model_len > 32768 if self.enable_chunked_prefill is None: if use_long_context and not model_config.is_multimodal_model: is_gpu = device_config.device_type == "cuda" use_sliding_window = (model_config.get_sliding_window() is not None) use_spec_decode = self.speculative_model is not None has_seqlen_agnostic_layers = ( model_config.contains_seqlen_agnostic_layers( parallel_config)) if (is_gpu and not use_sliding_window and not use_spec_decode and not self.enable_lora and not self.enable_prompt_adapter and not has_seqlen_agnostic_layers): self.enable_chunked_prefill = True logger.warning( "Chunked prefill is enabled by default for models with " "max_model_len > 32K. Currently, chunked prefill might " "not work with some features or models. If you " "encounter any issues, please disable chunked prefill " "by setting --enable-chunked-prefill=False.") if self.enable_chunked_prefill is None: self.enable_chunked_prefill = False # SchdulerConfig包括了max_num_batched_tokens(一个iteration最多处理多少个tokens), # max_num_seqs(一个iteration最多能处理多少数量的sequences以及 # max_seq_len(最大生成多长的context length, # 也就是一个sequence的最长长度,包含prompt部分和generated部分) scheduler_config = SchedulerConfig( max_num_batched_tokens=self.max_num_batched_tokens, max_num_seqs=self.max_num_seqs, max_model_len=model_config.max_model_len, use_v2_block_manager=self.use_v2_block_manager, num_lookahead_slots=num_lookahead_slots, delay_factor=self.scheduler_delay_factor, enable_chunked_prefill=self.enable_chunked_prefill, embedding_mode=model_config.embedding_mode, is_multimodal_model=model_config.is_multimodal_model, preemption_mode=self.preemption_mode, num_scheduler_steps=self.num_scheduler_steps, send_delta_data=(envs.VLLM_USE_RAY_SPMD_WORKER and parallel_config.use_ray), ) - 然后调用generate方法将传入的prompt传输上一步创建的AsyncEngine引擎
async def generate(request: Request) -> Response: request_dict = await request.json() # 将传入参数去掉prompt和stream数据 prompt = request_dict.pop("prompt") # 是否开启stream response stream = request_dict.pop("stream", False) # 生成logits采样参数 sampling_params = SamplingParams(**request_dict) # 为每一个request生成一个id request_id = random_uuid() # 调用引擎generate拿到response迭代器 results_generator = engine.generate(prompt, sampling_params, request_id) # 是否开启迭代器取消 results_generator = iterate_with_cancellation( results_generator, is_cancelled=request.is_disconnected) # 根据results_generator生成response迭代器,对应序号16 async def stream_results() -> AsyncGenerator[bytes, None]: async for request_output in results_generator: prompt = request_output.prompt assert prompt is not None text_outputs = [ prompt + output.text for output in request_output.outputs ] ret = {"text": text_outputs} yield (json.dumps(ret) + "\0").encode("utf-8") if stream: return StreamingResponse(stream_results()) - add_request这里会做两件事情:
- start_background_loop: 开启协程主循环,监听新request事件并处理, 对应线条4。
- 将request_tracker作为当前request的response stream追踪, 并将request放入到追踪队列,对应线条3
- engine_step是异步服务中较为核心的方法,主要会调用成员变量中的实际engine引擎,这个是个_AsyncLLEnginel类,对LLMEngine添加了一些异步封装方法。
- 首先会主动通过get_new_and_aborted_requests去tracker拿到相应的request(线条5)
- 然后调用add_request_async传入request请求(线条6、7), 这个不会调用模型中的tokenlizer做预处理和数据转换操作
- 随后我们获得token_ids后, 将token按照block分组,组成sequence,这个工程主要发生在内部函数_add_processed_request中,最后再讲sequence转换成seq_group数据结构,在prefill阶段,这里只有一条sequence。
- 随后会调用step_async,对request和此时生成的KVCache scheduler计划数据传给model(线条10、11)
- 模型的输出,会直接传入process_request_outputs中, 主要是把output放入到tracker中,最终关联上这个request的stream,返回给用户(线条13、14)
async def engine_step(self, virtual_engine: int) -> bool: # 首先会主动通过get_new_and_aborted_requests去tracker拿到相应的request(线条5) new_requests, aborted_requests = ( self._request_tracker.get_new_and_aborted_requests()) for new_request in new_requests: try: # 然后调用add_request_async传入request请求(线条6、7) await self.engine.add_request_async(**new_request) except ValueError as e: self._request_tracker.process_exception( new_request["request_id"], e, verbose=self.log_requests, ) if aborted_requests: await self._engine_abort(aborted_requests) # 随后会调用step_async,对request和此时生成的KVCache scheduler计划数据传给model(线条10、11) request_outputs = await self.engine.step_async(virtual_engine) # 没有定义request_outputs_callback函数,就使用默认的处理 if not self.use_process_request_outputs_callback: # 随后会调用step_async,对request和此时生成的KVCache scheduler计划数据传给model(线条10、11) # 模型的输出,会直接传入process_request_outputs中, 主要是把output放入到tracker中,最终关联上这个request的stream,返回给用户(线条13、14) all_finished = self.process_request_outputs(request_outputs) else: # 需要等到process_request_outputs_callback将所有request_output都设置为finished后,再返回 all_finished = all(request_output.finished for request_output in request_outputs) return not all_finished
2.2 LLM
LLM类是用于测试和同步调用时的封装,接口较为简单,我们先来看看其初始化参数
def __init__(self) -> None:
........
engine_args = EngineArgs(
# 模型定义名称
model=model,
# HF Transformers分词器的名称
tokenizer=tokenizer,
# 分词器模式。"auto"将使用快速分词器, "slow"将总是使用慢速分词器
tokenizer_mode=tokenizer_mode,
skip_tokenizer_init=skip_tokenizer_init,
# 当下载模型和分词器时,是否信任HF远程代码
trust_remote_code=trust_remote_code,
# 用于分布式执行的GPU数量,使用张量并行性。默认为1
tensor_parallel_size=tensor_parallel_size,
# 模型权重和激活的数据类型。目前,我们支持float32、float16和bfloat16。
# 如果是auto,我们使用在模型配置文件中指定的torch_dtype属性。
# 但是,如果配置中的torch_dtype是float32,我们将使用float16。默认为"auto"。
dtype=dtype,
# 用于量化模型权重的方法。目前,我们支持“awq”、“gptq”和“fp8”(实验性)。
# 如果为 None,我们首先检查模型配置文件中的 `quantization_config` 属性。
# 如果也为 None,我们假设模型权重未量化,并使用 `dtype` 来确定权重的数据类型
quantization=quantization,
# 默认0,表示不随机
seed=seed,
# GPU显存占用水位
gpu_memory_utilization=gpu_memory_utilization,
# cpu区域kvcache交换空间,默认4GB
swap_space=swap_space,
# 在cpu去开辟模型权重的存储空间,变相增加GPU显存
cpu_offload_gb=cpu_offload_gb,
# 默认打开eager(Extrapolation Algorithm for Greater Language-model Efficiency)算法加速,代替CUDA加速
enforce_eager=enforce_eager,
# CUDA Graph 相关参数,控制Graph优化间隔
max_context_len_to_capture=max_context_len_to_capture,
max_seq_len_to_capture=max_seq_len_to_capture,
# 使用NCLL代替all reduce kernal
disable_custom_all_reduce=disable_custom_all_reduce,
disable_async_output_proc=disable_async_output_proc,
**kwargs,
)
self.llm_engine = LLMEngine.from_engine_args(
engine_args, usage_context=UsageContext.LLM_CLASS)
self.request_counter = Counter()
LLM首先通过上文中的engine_args初始化LLMEgine,然后调用add_request接口,将prompt信息传入engine,此时engine会通过(路径8、9)来进行scheduler调度,最后12驱动模型,给出output。同步结构整体逻辑较为简单,就不详细展开。
3. LLMEngine
- 从上面代码可以看出,引擎是从from_engine_args方法入口创建的。这里重点说一下7、11、13这几条先的关键代码, 我们这次以LLM中如何使用LLMEngine为例,首先来看__init__定义
def __init__(self, ...) -> None:
# 保持各个核心子模块的配置文件
self.model_config = model_config
self.cache_config = cache_config
self.lora_config = lora_config
self.parallel_config = parallel_config
self.scheduler_config = scheduler_config
self.device_config = device_config
self.speculative_config = speculative_config
self.load_config = load_config
self.decoding_config = decoding_config or DecodingConfig()
self.prompt_adapter_config = prompt_adapter_config
self.observability_config = observability_config or ObservabilityConfig()
self.log_stats = log_stats
# 初始化token编码器tokenizer,解码器detokenizer
if not self.model_config.skip_tokenizer_init:
self.tokenizer = self._init_tokenizer()
self.detokenizer = Detokenizer(self.tokenizer)
tokenizer_group = self.get_tokenizer_group()
else:
self.tokenizer = None
self.detokenizer = None
tokenizer_group = None
# 通过模型配置中的start_token_id和是否为encode_decode_model等信息,进行不同的预处理
self.input_preprocessor = InputPreprocessor(model_config, self.tokenizer)
self.input_registry = input_registry
# 会绑定模型配置参数到input_processor方法中,由于模型加载的过程中已经做了注册。
# 因此input_processor就自然关联上了模型文件中的预处理方法。
self.input_processor = input_registry.create_input_processor(model_config)
# 初始化模型执行器,主要是对不同场景下的worker进行封装
self.model_executor = executor_class(
model_config=model_config,
cache_config=cache_config,
parallel_config=parallel_config,
scheduler_config=scheduler_config,
device_config=device_config,
lora_config=lora_config,
speculative_config=speculative_config,
load_config=load_config,
prompt_adapter_config=prompt_adapter_config,
observability_config=self.observability_config,
)
# 如果是嵌入式模型,需要先初始话kv_cache, 嵌入模型代表一些图片风格生成类的模型
if not self.model_config.embedding_mode:
# 根据GPU显存大小,确定初始化block size个数。
self._initialize_kv_caches()
# 初始化scheduler相关模块,这里会根据pipeline_parallel_size定义的并行数量,创建多个scheduler
self.cached_scheduler_outputs = [
SchedulerOutputState()
for _ in range(self.parallel_config.pipeline_parallel_size)
]
self.scheduler_contexts = [
SchedulerContext()
for _ in range(self.parallel_config.pipeline_parallel_size)
]
# for AsyncEngine
if model_config.use_async_output_proc:
process_model_outputs = weak_bind(self._process_model_outputs)
self.async_callbacks = [
partial(process_model_outputs,
ctx=self.scheduler_contexts[v_id])
for v_id in range(self.parallel_config.pipeline_parallel_size)
]
else:
self.async_callbacks = []
# Token block的核心模块
self.scheduler = [
Scheduler(
scheduler_config, cache_config, lora_config,
parallel_config.pipeline_parallel_size,
self.async_callbacks[v_id]
if model_config.use_async_output_proc else None)
for v_id in range(parallel_config.pipeline_parallel_size)
]
# 创建output后处理,判断是否这个sequence是finish状态
# 为 bean search 和 speculative decoding,在seq_group中生成更多的seq
self.output_processor = (
SequenceGroupOutputProcessor.create_output_processor(
self.scheduler_config,
self.detokenizer,
self.scheduler,
self.seq_counter,
get_tokenizer_for_seq,
stop_checker=StopChecker(
self.scheduler_config.max_model_len,
get_tokenizer_for_seq,
),
))
- add_request: 从上文得知,获取到的prompt,会经历tokenlize->sequence->sequence_group的数据处理操作,然后会作为参数传入add_seq_group
def add_request(
self,
request_id: str,
prompt: PromptType,
params: Union[SamplingParams, PoolingParams],
arrival_time: Optional[float] = None,
lora_request: Optional[LoRARequest] = None,
trace_headers: Optional[Mapping[str, str]] = None,
prompt_adapter_request: Optional[PromptAdapterRequest] = None,
) -> None:
if arrival_time is None:
arrival_time = time.time()
# promt -> tokenlize
preprocessed_inputs = self.input_preprocessor.preprocess(
prompt,
request_id=request_id,
lora_request=lora_request,
prompt_adapter_request=prompt_adapter_request,
)
processed_inputs = self.input_processor(preprocessed_inputs)
# tokenlize -> sequence_group
# 将sequence_group传入scheuler的add_seq_group方法进行KVCache的调度计算
self._add_processed_request(
request_id=request_id,
processed_inputs=processed_inputs,
params=params,
arrival_time=arrival_time,
lora_request=lora_request,
prompt_adapter_request=prompt_adapter_request,
trace_headers=trace_headers,
)
- step/step_async方法是进行推理的核心方法,会首先通过scheduler对sequence group进行KVCache调度,拿到调度之后的metadata,同各种缓存和队列一起,传入给模型执行器,执行器返回推理结果。
def step(self) -> List[Union[RequestOutput, EmbeddingRequestOutput]]:
virtual_engine = 0
# step函数是同步调用,只有一个scheduler,我们只使用给一个即可
cached_outputs = self.cached_scheduler_outputs[virtual_engine]
seq_group_metadata_list = cached_outputs.seq_group_metadata_list
scheduler_outputs = cached_outputs.scheduler_outputs
allow_async_output_proc = cached_outputs.allow_async_output_proc
ctx = self.scheduler_contexts[virtual_engine]
ctx.request_outputs.clear()
# 这次batch size,已经如果没有未完成的工作了
if not self._has_remaining_steps(seq_group_metadata_list):
# 开始新一次的调度迭代
(seq_group_metadata_list, scheduler_outputs,
allow_async_output_proc
) = self.scheduler[virtual_engine].schedule()
ctx.seq_group_metadata_list = seq_group_metadata_list
ctx.scheduler_outputs = scheduler_outputs
# 同步调用,使用同步方法做模型的后处理
# 根据request_id,将生成的token,展开到sequence group中
if not allow_async_output_proc and len(ctx.output_queue) > 0:
self._process_model_outputs(ctx=ctx)
if (self.scheduler_config.is_multi_step
and scheduler_outputs.num_lookahead_slots > 0):
# 缓存上次的输出,用于下一次的输入
self._cache_scheduler_outputs_for_multi_step(
virtual_engine, seq_group_metadata_list, scheduler_outputs,
allow_async_output_proc)
assert seq_group_metadata_list is not None
assert scheduler_outputs is not None
if not scheduler_outputs.is_empty():
finished_requests_ids = self.scheduler[
virtual_engine].get_and_reset_finished_requests_ids()
# 在每个引擎内部获取sample_token_id缓存,为了并发场景下,可以向worker传递此token
last_sampled_token_ids = \
self._get_last_sampled_token_ids(virtual_engine)
execute_model_req = ExecuteModelRequest(
seq_group_metadata_list=seq_group_metadata_list,
blocks_to_swap_in=scheduler_outputs.blocks_to_swap_in,
blocks_to_swap_out=scheduler_outputs.blocks_to_swap_out,
blocks_to_copy=scheduler_outputs.blocks_to_copy,
num_lookahead_slots=scheduler_outputs.num_lookahead_slots,
running_queue_size=scheduler_outputs.running_queue_size,
finished_requests_ids=finished_requests_ids,
last_sampled_token_ids=last_sampled_token_ids)
if allow_async_output_proc:
execute_model_req.async_callback = self.async_callbacks[
virtual_engine]
# 同步发送给执行器
outputs = self.model_executor.execute_model(
execute_model_req=execute_model_req)
# 向缓存中存储last_sampled_token_ids,用于下次迭代.
if self.scheduler_config.is_multi_step:
self._update_cached_scheduler_output(virtual_engine, outputs)
else:
# 都完成了,那么无需模型执行器参与,直接就处理输出结果就好了。
if len(ctx.output_queue) > 0:
self._process_model_outputs(ctx=ctx)
# No outputs in this case
outputs = []
# 将当前这次step数+1.
if self.scheduler_config.is_multi_step:
for seq_group in seq_group_metadata_list:
seq_group.finish_step()
# 没有剩余的step,我们讲缓存存入第一个缓存中(只针对step同步调用)
if not self._has_remaining_steps(seq_group_metadata_list):
if self.scheduler_config.is_multi_step:
self.cached_scheduler_outputs[0] = SchedulerOutputState()
# Add results to the output_queue
ctx.append_output(outputs=outputs,
seq_group_metadata_list=seq_group_metadata_list,
scheduler_outputs=scheduler_outputs,
is_async=allow_async_output_proc,
is_last_step=True)
if outputs and allow_async_output_proc:
assert len(outputs) == 1, (
"Async postprocessor expects only a single output set")
self._advance_to_next_step(
outputs[0], seq_group_metadata_list,
scheduler_outputs.scheduled_seq_groups)
else:
return ctx.request_outputs
# 当前sequence group中没有新的request,我们将最后的output处理完毕后,停止模型的运行
if not self.has_unfinished_requests():
# Drain async postprocessor (if exists)
if len(ctx.output_queue) > 0:
self._process_model_outputs(ctx=ctx)
assert len(ctx.output_queue) == 0
logger.debug("Stopping remote worker execution loop.")
self.model_executor.stop_remote_worker_execution_loop()
return ctx.request_outputs
4.总结
本文通过图解的方式给出LLMEngine处理的主逻辑,并分模块进行了核心代码的讲解。LLMEngine作为上层核心调度层,串联起Scheduler和ModelExecutor两个下层核心模块。
后面的文章我们会重点介绍Scheduler,它是对vLLM中的PageAttention的核心加速理论的具体实现,敬请期待。