- 图解vllm-原理与架构
- 图解vllm-推理服务与引擎
- 图解vllm-调度器与Block分配
- 图解vllm-执行器与worker
- 图解vllm-model之model和attention_backend
2024年,我们已经进入大模型全面爆发的时代,作为大模型很重要的工程实践: 推理服务,则成为熟悉和了解大模型工程的关键一环。vLLM是23年开始出现的一款较为优秀的大模型推理框架,很值得学习和研究,我将发布一系列的Blog,针对近期学习vLLM的主要内容,通过图解的方式从工程和算法角度进行总结。本篇文章主要关注于vLLM的原理与整体架构,构建一个全貌,后面的文章会分层逐步细化代码具体实现。
1. Transformer架构模型与KVCache
目前大模型都是基于Transformer架构进行设计,transformer的核心能力是其对输入上下文进行SelfAttention,从而获得跟输入信息最相关的信息量,作为下一层step的输入,最终通过一些forward和normalization,得到最终的概率分布。
1.1 SelfAttention
自注意力可以用如下公式1进行表达
$Attention(Q, K, V)=softmax(\frac{QK^T}{\sqrt{b_k}})\quad\quad\quad(1)$
以上公式可进一步进行分解:
- 将输入的序列 映射到三个向量空间中,分别得到三个向量$q, k, v$, 对应公式2
- 计算$q, k$向量匹配度,得到注意力得分$a_{ij}$,表示第 i 个位置的 token 和第 j 个位置的 token 的匹配度得分。各注意力得分组成一个向量$a_i$,表示第$i$个位置的 token 和以前其余位置所有token的得分向量
- 注意力得分向量$a_i$与向量$v$做内积,得到SelfAttention的最终输出$o_i$, 对应公式3
$q_i = W_qx_i,\quad k_i = W_kx_i,\quad v_i = W_vx_i,\quad\quad\quad(2)$
$a_{ij} = {exp(q^T_i/\sqrt{d}) \over \sum_{t=1}^iexp(q^T_t/\sqrt{d})},\quad o_i = \sum_{j=1}^i{a_{ij}v_j}\quad\quad\quad(3)$,
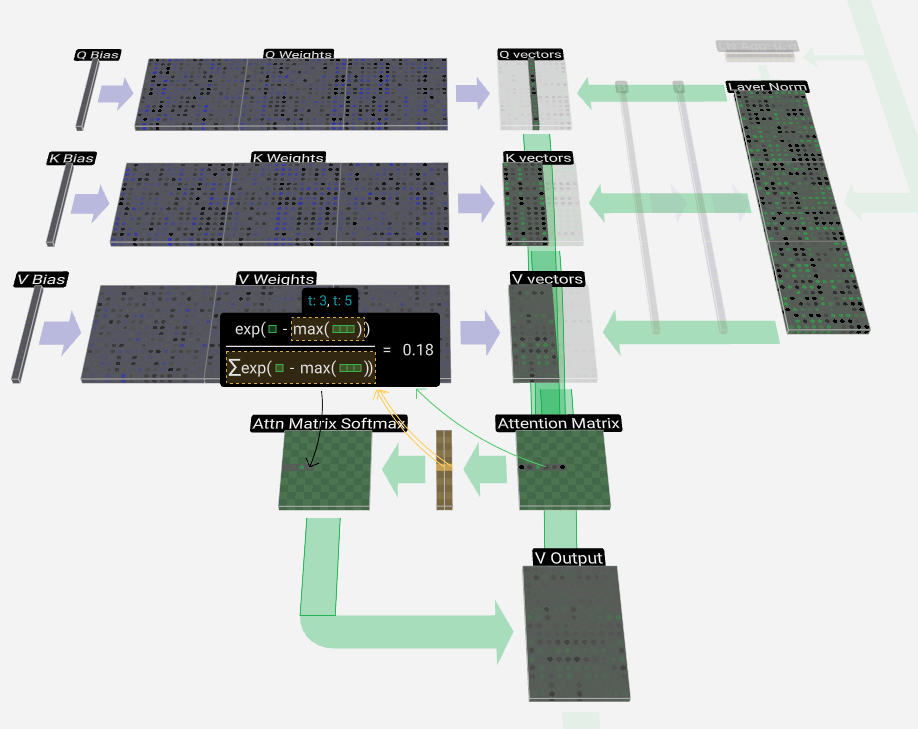
上图就是Transformer中,公式2和公式3的具体求解过程图解
1.2 KVCache
通过公式3和图解可知,对于SelfAttention来说,在计算$a_{ij}$时,除了需要公式2计算得到的$q_i, k_i, v_i$,还需要$k_i, v_i(j < i)$。由于之前迭代生成第$j$个token时已经计算过了$k_i, v_i(j < i)$, 并且后续迭代生成可以直接复用这部分$k_i, v_i$,所以Transformer相关模型在所计算时,都使用缓存的方式,将计算过的$k, v$向量缓存到显存中,避免每次迭代重复计算这两个向量, 因此向量的缓存就是大家熟知的 KVCache了。
2. 推理服务优化目标
根据上文,如何利用的KVCache原理,用最少的资源获得最大的吞吐量,就是推理服务突破瓶颈的关键目标。
在推理过程中,主要分为两个阶段: Prefill 和 Decode 阶段
- Prefill: 即用户输出prompt阶段,推理服务器会根据prompt解析出token序列,然后使用token序列去初始化GPU显存中的KVCache数据,并预测下一个生成的token。
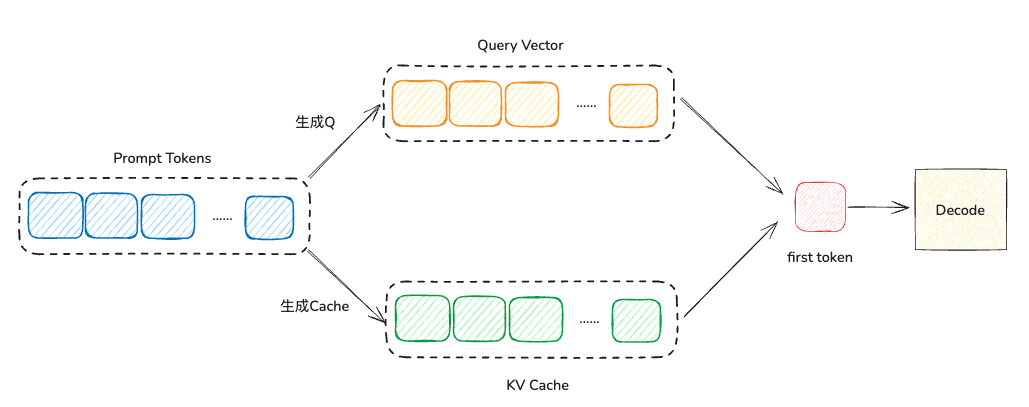
- Decode: 接下来针对产生的新token,进行循环迭代,直到达到最大生成长度或者终止符为止;迭代生成每个 token。在生成第$t+1$个token时,需要将 prompt token、已生成的 token 及当前第$t$个token的KVCache拼接起来,与第$t$个token的query vector完成SelfAttention等计算。完成当前迭代的token生成时,若生成的token为终止符或者生成的长度到达最大长度,则停止迭代。
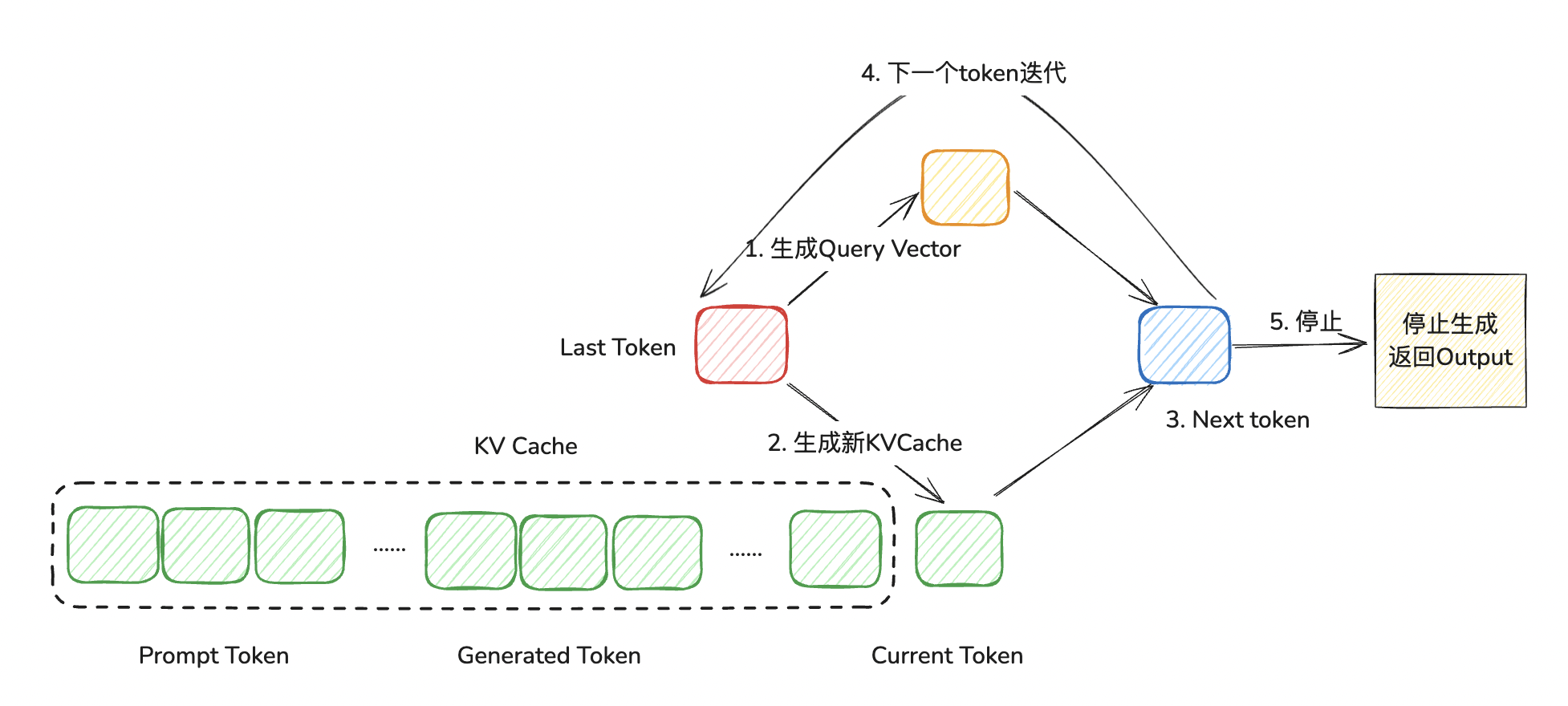
在 LLM 服务中,由于Decode阶段生成token时依赖之前生成的token,无法并行生成多个token,只能串行迭代生成。因此会影响整体推理服务吞吐。那么如何提升整体吞吐量,我们先了解一下GPU内存分布。显存占用主要由三部分组成:模型权重、KVCache 以及其他激活值,KVCach 和激活值显存开销又与推理时的batch size成正比。
在论文中,以A100 40GB为例,LLaMA-13B BF16 模型的显存占比。模型权重有26GB,其余显存均用来存储KVCache和激活值。设置最大batch size使KVCache和激活值显存占满剩余显存空间,那么KVCache的显存占比大于30%,激活值显存占比不及5%

所以想提高吞吐量,就是要提高KVCache的内存占用大小,我们来看一下内存占用的公式:
KVCacheMemory = 2 * batch_size * max_seq_len * num_layers * hidden_size * num_heads * dtype_size
从公式中可以看出,KVCache显存开销与batch_size、num_layers、max_seq_len、hidden_size、num_heads以及数值类型大小六个维度相关。在KVCache 显存开销上限一定的情况下,为了提升单次推理最大合并请求数,也就是batch_size的值,可通过降低其他几个维度的值来提升。因此我们可以尝试如下几个方面进行优化:
2.1 数值类型量化
训练时通常使用FP16数值类型,在推理阶段可使用int8量化,降低数值类型大小。如使用KVCache int8量化, 这会使batch_size增加一倍。
2.2 模型精简
num_layers、hidden_size、num_heads:理论上可以通过剪枝等稀疏化的方式,降低这两个维度的值, 这个并不是本文的重点内容,暂时不深入探讨。
2.3 Batching
我可以在单次请求中尽量多的放入prompt request序列,同时也在某些request完成输出后,及时的插入新的reqeust,填满batch size,具体可以通过下面图示理解
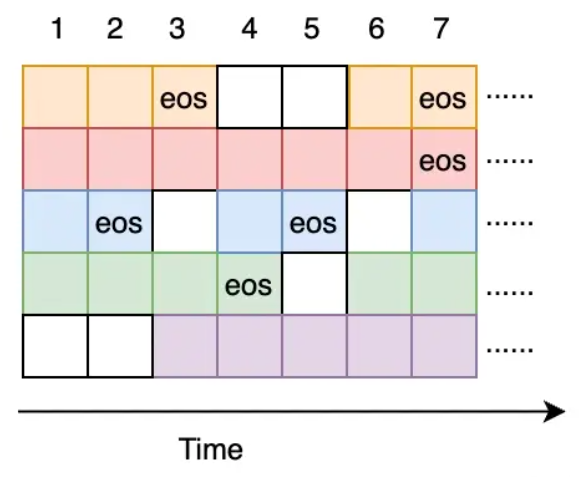
- 延时方面:可以大幅度降低请求端到端延时。由于队列的请求在Decode阶段动态地插入到 Batch,所以请求的队列等待时间从原来的秒级别下降到毫秒级别(仅需等待一轮迭代即可插入到Batch中)。
- 资源利用率方面:提升GPU资源有效利用率。由于队列的请求在Decode阶段每一轮结束后动态地插入到Batch,而Batch也在迭代过程中动态地删除已完成推理的请求,这样避免了GPU空转,提升资源利用率。
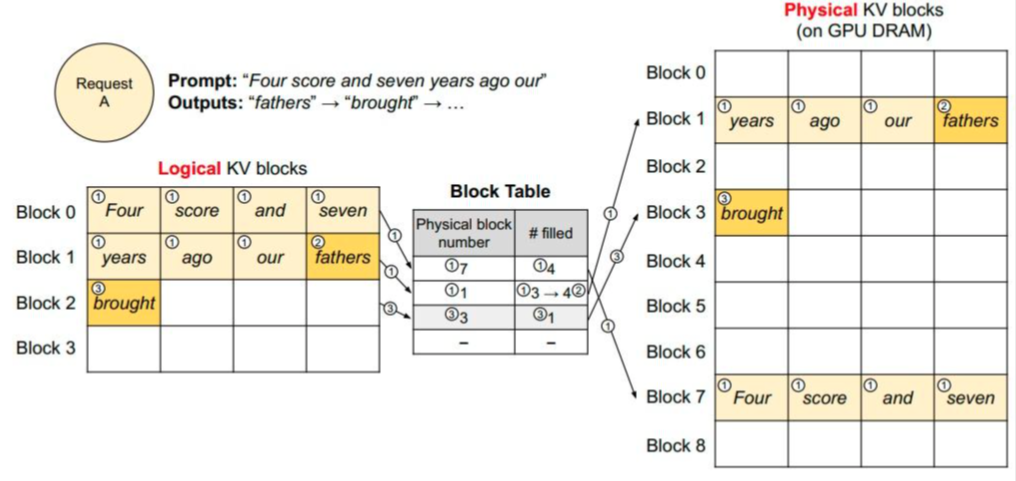
2.4 PageAttention
那么还有一个维度,就是max_seq_len: token的最大长度, 这是一个固定值。gpt2中的大小是2048。在Prefill和decode阶段,KV向量是一次性初始化后在逐步递增,这就要求在空间上排列是连续的。因此如果实际按照max_seq_len的大小进行KVCache的实际预留和分配,必然会提前占用很多还未使用的空间,显存利用率会明显降低。并且空间回收后还会留下很多存储碎片,印象下次分配决策。
vLLM框架论文中提出了PageAttention,原理是借鉴操作系统对虚拟内存设计,也就是对KVCache进行划分,每个KVCache块包含若干个固定tokens的 key、value向量, 称之为一个Block。vLLM会维护一个block_table, 这是一个逻辑Block和物理Block的映射表。逻辑上看,多组Block在虚拟空间上是连续的,但从实际分配上看,这样我们可以对物理显存上的Block添加管理策略,每个Block在物理显存上可以动态的、不连续的实时分配;
使用页管理内存还有一个好处,就是用户无需提前分配足够的内存,可以按需分配内存。vLLM也借鉴了swap内存页的管理算法,在LLM服务中管理KVCache显存。当物理内存不足时,又可以通过和CPU中的内存进行灵活交换物理显存内容,从而高效利用gpu显存,增加并发的prompt数量,提升整体吞吐量。
2.5 FlashAttention
PageAttention解决的事CPU层的逻辑层到GPU的物理层的内存管理算法,那么当KVCache全部加载到GPU显存后,如果再进行加速,这也是一个比较重要的提速方向。
GPU的内存类型分为HBM(显存)、SRAM(高速缓存),并且SRAM中还分为L1、L2量级缓存,在GPU中每个SM(Stream Multiprocessors)会独享L1缓存,但是多个SM会共享L2缓存。FlashAttention就是利用数学分解的方式,在进行attention计算过程中减少中间计算结果,充分利用L1+L2缓存,提高计算速度。下图大致描述了FlashAttention的计算过程。
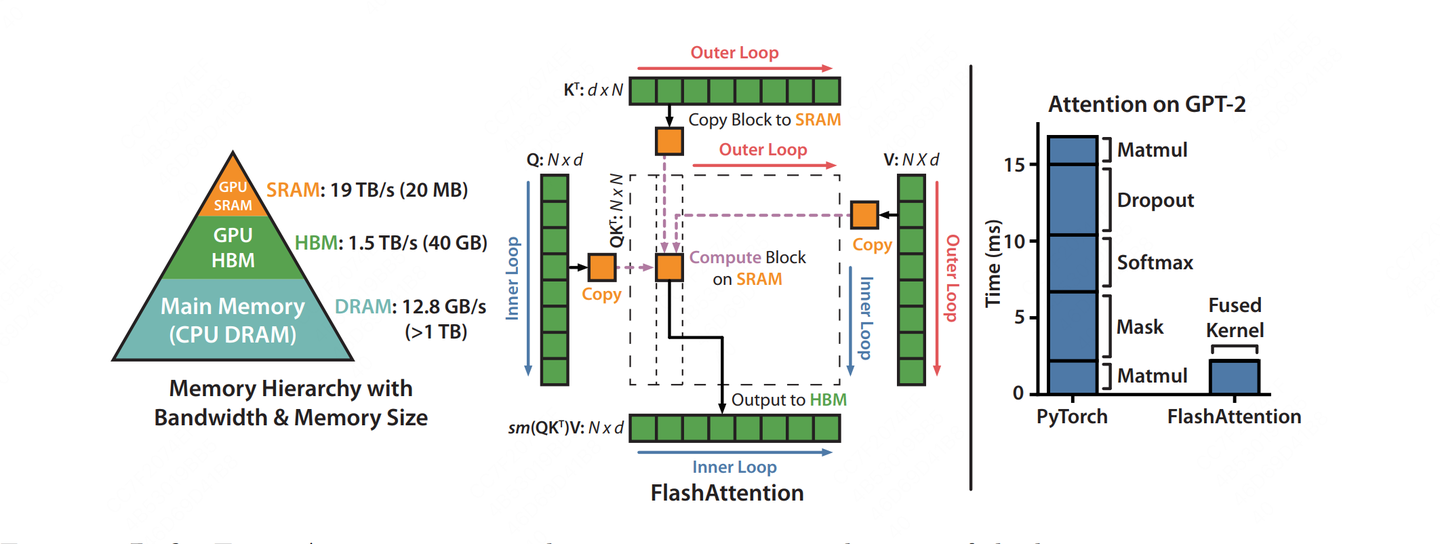
具体内容不再进行展开,后面我也会学习完CUDA kernal相关知识后,补充这块的学习总结文章。
3. vLLM分层架构
了解完上面推理服务的一些理论内容后,我们开始描述一下vLLM的架构,vLLM作为目前较为活跃的开源项目,每天有大量的提交,截止此文章发布之时,是按照0.6.1的版本进行的架构梳理,如果发现实际代码与本文描述不一致,很可能是这部分内容有所更新。我也会及时跟进最新的变化,更新文章内容。下面我们来看一下vLLM的整体分层架构图。
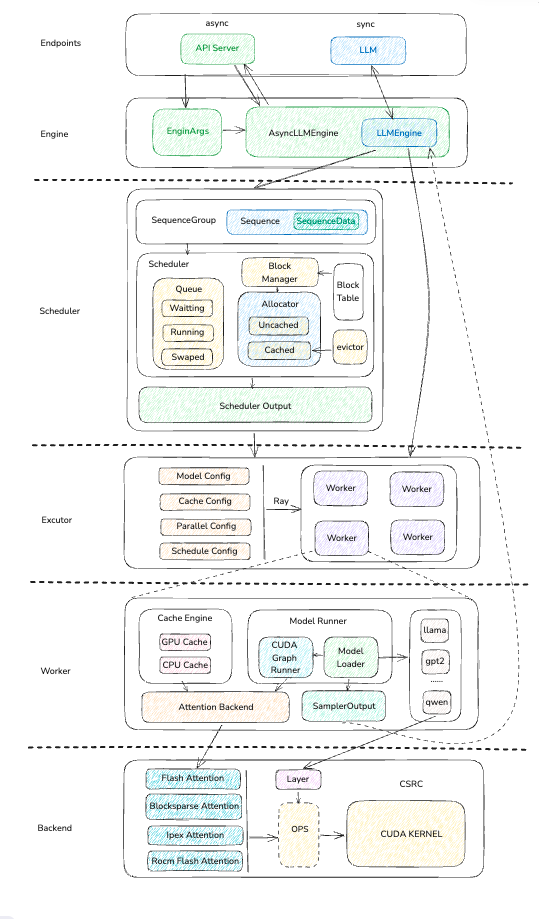
3.1 Endpoints/Engine:
-
Endpoints层是整个推理服务的入口,用于传入模型类型、推理参数、对于没一个request返回其output结果合集。
API Server是一个异步服务端,它会为每一个request关联一个output stream,用来返回推理生成的结果。
LLM多数用在同步代码和测试代码当中,他是对下层引擎的封装,并将引用层传入的参数组成engine_arges, 提供给引擎。
-
Engine层推理服务的核心控制层,一方面他会创建Scheduler,并传入request规划好需要使用的KVCache,另一方面初始化模型执行器,并将KVCache和request灌入执行器,最后得到模型的执行器返回给用户。
3.2 Scheduler:
-
作为PageAttention的核心调度层,首先会把request转换为SequenceGroup,这样当我们使用例如Bean Search这些并行token生成策略的时,这一个requst就会变成一组相关token序列,我们为每个序列生成目标token,并选取其中最符合当前策略的token作为下一轮输入和结果输出。
-
Scheduler维护了3个队列,其中waitting队列主要是用户刚刚输入到scheuler中的token序列;running队列是正在进行推理的token序列;swaped队列是当显存不足或者推理优先级降低时,从GPU中换出的token序列
-
另外一个比较重要的事BlockManager,目前vLLM中有两个版本V1,V2,目前V2版本还未完全开发完毕,例如还没有支持prefix token的功能,所以暂时不会讨论这个版本,接下来的文章会研究V1版本的BlockManager。
-
BlockManager下属两个KVCache分配器: UncachedAllocator、CachedAllocator. UncachedAllocator是我们前文提到的正常token的KVCache分配器, 通过block_table维护分配状态,CachedAllocator略有差别,他主要添加了token前缀hash计算,会将相同前缀的KVCache直接复用起来,并引入了evcitor等概念,被清除的KVCache会先暂时根据LRU原则转移到evcitor中,如果短时间内又出现相同前缀的token,可以恢复他的前缀KVCache使用。
-
在Scheduler Output封装中,我们会将调度的KVCache和相关的sequence id传入给模型,这样就可以直接使用进行推理了。
3.3 Excutor:
执行器主要是通过worker的一种封装,其中既有单卡单worker的封装形式,同时也有分布式集群的worker形式,我们在接下来的梳理中主要是关注通过ray分布式框架组织的worker集群的运行模式。
3.4 Worker:
对应每个Worker,不仅需要负责加载实际的模型,同时对需要对不同模型的推理逻辑进行捕获,使用CUDA Graph加速推理效率。
上文提到BlockManager会通过block_table规划好哪些物理Block需要使用,到了worker这一层就是对具体的物理内存进行操作。
以上动作都会直接和GPU或者其他计算平台打交道,因此还会封装一层Attention Backend, 屏蔽这些不同平台的差异细节。
最终我们可以获得模型的logits输出,通过我们的sample策略后,得出最终的Output, 返回给上一层。
3.5 Backend:
Backend这层主要关注于推理和模型层计算过程中需要用到的各种加速算法和技巧。我会重点分析FlashAttention相关的调用逻辑,最后通过OPS的粘结剂层将最终的数据GPU中,最终执行相关的kernel函数进行并行计算。
4. 总结
本文首先科普了Transformer大模型在推理过程中的基础理论支持,和推理服务的重点关注目标。然后介绍了vLLM的分层架构,后面的文章我们会那种目前的大致分层,结合图解和代码,详细介绍具体实现逻辑,敬请期待。