- 图解vllm-原理与架构
- 图解vllm-推理服务与引擎
- 图解vllm-调度器与Block分配
- 图解vllm-执行器与worker
- 图解vllm-model之model和attention_backend
调度器(Scheduler)决定哪些请求可以参与推理,并为这些请求做好逻辑块->物理块的映射。这个过程只是根据目前step(prefill+decode)收集到的所有信息,对目前GPU的显存进行新的内存分配规划,而未实际操作GPU内存。在模型执行器中,这些规划metadata会最终执行,正式分配相应的内存。下面我们展开调度器中的细节。
1. 调度器图解
调度分为两步进行:
- 添加引擎提供的sequence group数据,存储至waitting队列。
- 对目前调度队列中的任务进行遍历和重新分配,需要修改成running状态的,需要对应分配物理block,同时根据资源情况进行swap int/out。整体图解如下
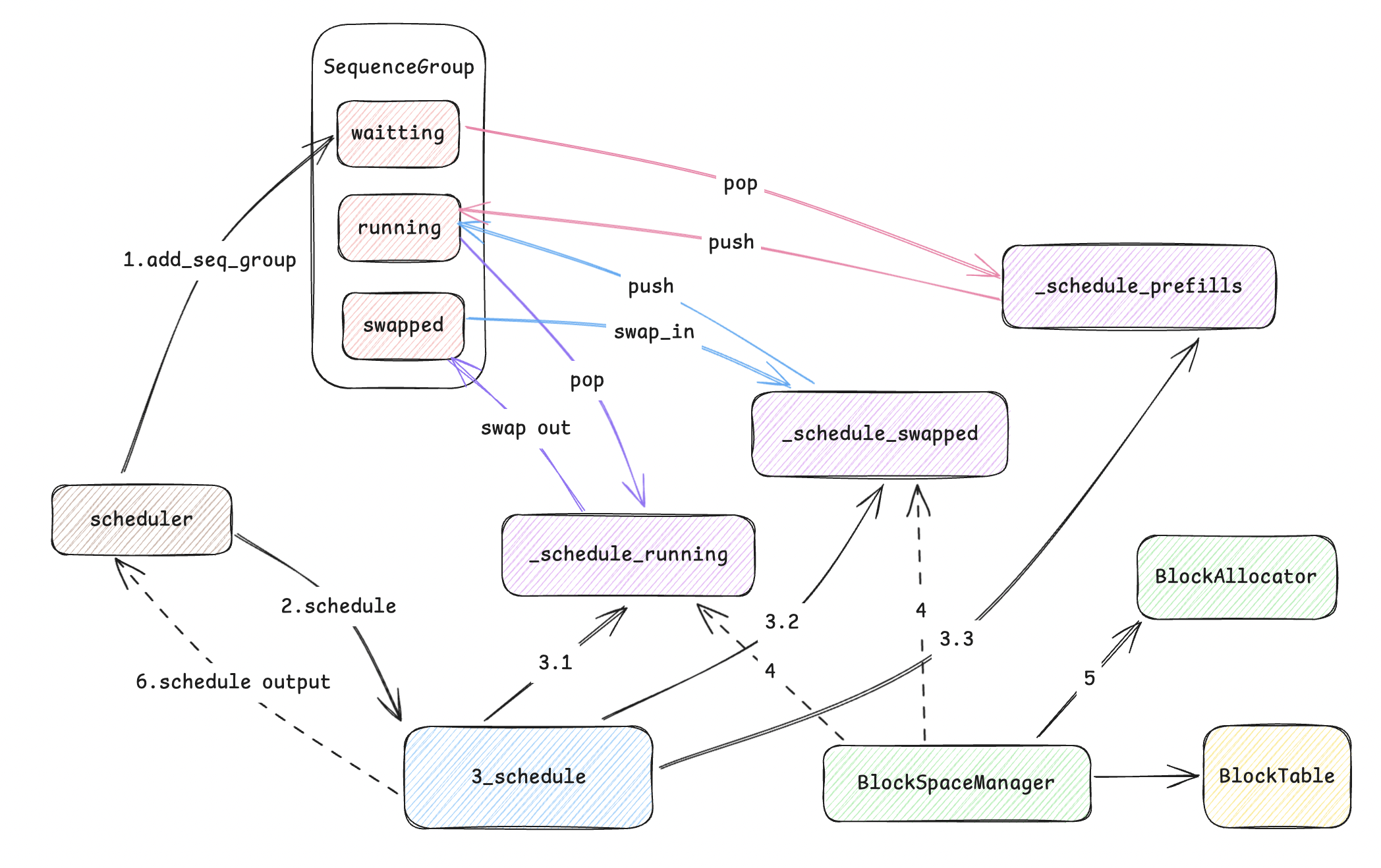
2. Scheduler
从上图图解可以看出,首先通过add_seq_group添加到waitting队列后,引擎对调用schedule方法通知调度器进行调度,本文以支持性能调度的chunked_prefill为例进行讲解。调度后,scheduler还会对调度的输出进行简单的后处理,缓存相关的结果为下一步迭代做准备。
注:chunked prefill是在prefill阶段不会一次性的处理完所有prefill, 我们会根据prefill的大小规划后面的budget,从而后面每次迭代(prefill+decode)都会带上这个prefill request id的处理,针对长prompt可以显著提高TTFT指标
2.1 scheduler sequence group
- 调度器首先从规划running队列的数据,将已完成的数据状态标记为finished,然后评估资源情况,对无法调度的sg放入swapped队列,对于sg size只有1的请求,直接放入watting队列,作为全新的request处理,代码如下:
def _schedule_running(
self,
budget: SchedulingBudget,
curr_loras: Optional[Set[int]],
enable_chunking: bool = False,
) -> SchedulerRunningOutputs:
# 从缓存中找一个位置,进行输出信息存储
ret: SchedulerRunningOutputs = \
self._scheduler_running_outputs_cache[self.cache_id].get_object()
ret.blocks_to_swap_out.clear()
ret.blocks_to_copy.clear()
ret.decode_seq_groups.clear()
ret.prefill_seq_groups.clear()
ret.preempted.clear()
ret.swapped_out.clear()
ret.num_lookahead_slots = self._get_num_lookahead_slots(
is_prefill=False)
ret.decode_seq_groups_list.clear()
ret.prefill_seq_groups_list.clear()
blocks_to_swap_out: List[Tuple[int, int]] = ret.blocks_to_swap_out
blocks_to_copy: List[Tuple[int, int]] = ret.blocks_to_copy
decode_seq_groups: List[ScheduledSequenceGroup] = ret.decode_seq_groups
prefill_seq_groups: List[
ScheduledSequenceGroup] = ret.prefill_seq_groups
preempted: List[SequenceGroup] = ret.preempted
swapped_out: List[SequenceGroup] = ret.swapped_out
running_queue = self.running
assert len(self._async_stopped) == 0
# 遍历所有队列元素
while running_queue:
seq_group = running_queue[0]
# 获取此sg中还需要调度的token数
num_running_tokens = self._get_num_new_tokens(
seq_group, SequenceStatus.RUNNING, enable_chunking, budget)
if num_running_tokens == 0:
# No budget => Stop
break
running_queue.popleft()
# 控制在异步处理时,额外decode资源过载
if self.use_async_output_proc and seq_group.seqs[0].get_len(
) > self.scheduler_config.max_model_len:
self._async_stopped.append(seq_group)
continue
# NOTE(woosuk): 没有槽位,将当前操作元素放入swaped队列或者waitting队列
while not self._can_append_slots(seq_group):
budget.subtract_num_batched_tokens(seq_group.request_id,
num_running_tokens)
num_running_seqs = seq_group.get_max_num_running_seqs()
budget.subtract_num_seqs(seq_group.request_id,
num_running_seqs)
if (curr_loras is not None and seq_group.lora_int_id > 0
and seq_group.lora_int_id in curr_loras):
curr_loras.remove(seq_group.lora_int_id)
# ....
# Do preemption
if do_preempt:
preempted_mode = self._preempt(victim_seq_group,
blocks_to_swap_out)
if preempted_mode == PreemptionMode.RECOMPUTE:
preempted.append(victim_seq_group)
else:
swapped_out.append(victim_seq_group)
if not cont_loop:
break
else:
self._append_slots(seq_group, blocks_to_copy)
is_prefill = seq_group.is_prefill()
scheduled_seq_group: ScheduledSequenceGroup = \
self._scheduled_seq_group_cache[self.cache_id].get_object()
scheduled_seq_group.seq_group = seq_group
# prefill阶段,更新处理多少token
if is_prefill:
scheduled_seq_group.token_chunk_size = num_running_tokens
prefill_seq_groups.append(scheduled_seq_group)
ret.prefill_seq_groups_list.append(seq_group)
else:
# decode阶段,每次都处理一个
scheduled_seq_group.token_chunk_size = 1
decode_seq_groups.append(scheduled_seq_group)
ret.decode_seq_groups_list.append(seq_group)
budget.add_num_batched_tokens(seq_group.request_id,
num_running_tokens)
# 如果是chunk prefill,计算剩余的步数
if enable_chunking:
num_running_seqs = seq_group.get_max_num_running_seqs()
budget.add_num_seqs(seq_group.request_id, num_running_seqs)
if curr_loras is not None and seq_group.lora_int_id > 0:
curr_loras.add(seq_group.lora_int_id)
# 清除本次step缓存
self._scheduler_running_outputs_cache[self.next_cache_id].reset()
self._scheduled_seq_group_cache[self.next_cache_id].reset()
return ret
- 处理完running队列后,会再处理swap队列,处理需要swap in/out的sg。swap out时,针对prefill对放入prefill group中。针对无调度空间的sg,放弃调度,标记为finished状态。
def _schedule_swapped(
self,
budget: SchedulingBudget,
curr_loras: Optional[Set[int]],
enable_chunking: bool = False,
) -> SchedulerSwappedInOutputs:
# Blocks that need to be swapped or copied before model execution.
blocks_to_swap_in: List[Tuple[int, int]] = []
blocks_to_copy: List[Tuple[int, int]] = []
decode_seq_groups: List[ScheduledSequenceGroup] = []
prefill_seq_groups: List[ScheduledSequenceGroup] = []
infeasible_seq_groups: List[SequenceGroup] = []
swapped_queue = self.swapped
leftover_swapped: Deque[SequenceGroup] = deque()
while swapped_queue:
seq_group = swapped_queue[0]
# If the sequence group cannot be swapped in, stop.
is_prefill = seq_group.is_prefill()
# 空间不足,再等等
alloc_status = self.block_manager.can_swap_in(
seq_group, self._get_num_lookahead_slots(is_prefill))
if alloc_status == AllocStatus.LATER:
break
# 标记为finished
elif alloc_status == AllocStatus.NEVER:
logger.warning(
"Failing the request %s because there's not enough kv "
"cache blocks to run the entire sequence.",
seq_group.request_id)
for seq in seq_group.get_seqs():
seq.status = SequenceStatus.FINISHED_IGNORED
infeasible_seq_groups.append(seq_group)
swapped_queue.popleft()
continue
lora_int_id = 0
if self.lora_enabled:
lora_int_id = seq_group.lora_int_id
assert curr_loras is not None
assert self.lora_config is not None
if (lora_int_id > 0 and (lora_int_id not in curr_loras)
and len(curr_loras) >= self.lora_config.max_loras):
# We don't have a space for another LoRA, so
# we ignore this request for now.
leftover_swapped.appendleft(seq_group)
swapped_queue.popleft()
continue
# The total number of sequences in the RUNNING state should not
# exceed the maximum number of sequences.
num_new_seqs = seq_group.get_max_num_running_seqs()
num_new_tokens = self._get_num_new_tokens(seq_group,
SequenceStatus.SWAPPED,
enable_chunking, budget)
if (num_new_tokens == 0
or not budget.can_schedule(num_new_tokens=num_new_tokens,
num_new_seqs=num_new_seqs)):
break
if lora_int_id > 0 and curr_loras is not None:
curr_loras.add(lora_int_id)
swapped_queue.popleft()
self._swap_in(seq_group, blocks_to_swap_in)
self._append_slots(seq_group, blocks_to_copy)
is_prefill = seq_group.is_prefill()
if is_prefill:
prefill_seq_groups.append(
ScheduledSequenceGroup(seq_group,
token_chunk_size=num_new_tokens))
else:
decode_seq_groups.append(
ScheduledSequenceGroup(seq_group, token_chunk_size=1))
budget.add_num_batched_tokens(seq_group.request_id, num_new_tokens)
budget.add_num_seqs(seq_group.request_id, num_new_seqs)
swapped_queue.extendleft(leftover_swapped)
return SchedulerSwappedInOutputs(
decode_seq_groups=decode_seq_groups,
prefill_seq_groups=prefill_seq_groups,
blocks_to_swap_in=blocks_to_swap_in,
blocks_to_copy=blocks_to_copy,
num_lookahead_slots=self._get_num_lookahead_slots(
is_prefill=False),
infeasible_seq_groups=infeasible_seq_groups,
)
- 最后我们再观察waitting队列,将可以分配的sg规划好KVCache,标记为running状态,不满足资源的sg继续放在waitting队列里直到条件满足时再进行处理。
def _schedule_prefills(
self,
budget: SchedulingBudget,
curr_loras: Optional[Set[int]],
enable_chunking: bool = False,
) -> SchedulerPrefillOutputs:
ignored_seq_groups: List[SequenceGroup] = []
seq_groups: List[ScheduledSequenceGroup] = []
waiting_queue = self.waiting
leftover_waiting_sequences: Deque[SequenceGroup] = deque()
while self._passed_delay(time.time()) and waiting_queue:
seq_group = waiting_queue[0]
waiting_seqs = seq_group.get_seqs(status=SequenceStatus.WAITING)
assert len(waiting_seqs) == 1, (
"Waiting sequence group should have only one prompt "
"sequence.")
# 在chunk prefill阶段,我们需要根据budget个数计算tokens
# decode阶段,计算所有group中的token个数
num_new_tokens = self._get_num_new_tokens(seq_group,
SequenceStatus.WAITING,
enable_chunking, budget)
if not enable_chunking:
num_prompt_tokens = waiting_seqs[0].get_len()
assert num_new_tokens == num_prompt_tokens
prompt_limit = self._get_prompt_limit(seq_group)
# 超过设置的限制,直接丢弃
if num_new_tokens > prompt_limit:
logger.warning(
"Input prompt (%d tokens) is too long"
" and exceeds limit of %d", num_new_tokens, prompt_limit)
for seq in waiting_seqs:
seq.status = SequenceStatus.FINISHED_IGNORED
ignored_seq_groups.append(seq_group)
waiting_queue.popleft()
continue
# If the sequence group cannot be allocated, stop.
can_allocate = self.block_manager.can_allocate(seq_group)
# 不能分配KV空间,下轮再说
if can_allocate == AllocStatus.LATER:
break
elif can_allocate == AllocStatus.NEVER:
# 丢弃
logger.warning(
"Input prompt (%d tokens) is too long"
" and exceeds the capacity of block_manager",
num_new_tokens)
for seq in waiting_seqs:
seq.status = SequenceStatus.FINISHED_IGNORED
ignored_seq_groups.append(seq_group)
waiting_queue.popleft()
continue
lora_int_id = 0
if self.lora_enabled:
lora_int_id = seq_group.lora_int_id
assert curr_loras is not None
assert self.lora_config is not None
if (self.lora_enabled and lora_int_id > 0
and lora_int_id not in curr_loras
and len(curr_loras) >= self.lora_config.max_loras):
# We don't have a space for another LoRA, so
# we ignore this request for now.
leftover_waiting_sequences.appendleft(seq_group)
waiting_queue.popleft()
continue
num_new_seqs = seq_group.get_max_num_running_seqs()
if (num_new_tokens == 0
or not budget.can_schedule(num_new_tokens=num_new_tokens,
num_new_seqs=num_new_seqs)):
break
# Can schedule this request.
if curr_loras is not None and lora_int_id > 0:
curr_loras.add(lora_int_id)
waiting_queue.popleft()
# 分配空间并标记running状态
self._allocate_and_set_running(seq_group)
# 规划chunked prefill迭代次数
seq_group.init_multi_step(
num_scheduler_steps=self._get_num_lookahead_slots(
is_prefill=True) + 1)
seq_groups.append(
ScheduledSequenceGroup(seq_group=seq_group,
token_chunk_size=num_new_tokens))
budget.add_num_batched_tokens(seq_group.request_id, num_new_tokens)
budget.add_num_seqs(seq_group.request_id, num_new_seqs)
# Queue requests that couldn't be scheduled.
waiting_queue.extendleft(leftover_waiting_sequences)
if len(seq_groups) > 0:
self.prev_prompt = True
return SchedulerPrefillOutputs(
seq_groups=seq_groups,
ignored_seq_groups=ignored_seq_groups,
num_lookahead_slots=self._get_num_lookahead_slots(is_prefill=True))
- 最后_schedule_chunked_prefill方法的末尾,我们收集上面所有已经调度好的sg,封装成SchedulerOutputs对外输出
def _schedule_chunked_prefill(self) -> SchedulerOutputs:
# ...
return SchedulerOutputs(
# 所有需要执行的sg
scheduled_seq_groups=(prefills.seq_groups +
running_scheduled.prefill_seq_groups +
swapped_in.prefill_seq_groups +
running_scheduled.decode_seq_groups +
swapped_in.decode_seq_groups),
# 所有prefill的sg
num_prefill_groups=(len(prefills.seq_groups) +
len(swapped_in.prefill_seq_groups) +
len(running_scheduled.prefill_seq_groups)),
# 已经处理的token数量
num_batched_tokens=budget.num_batched_tokens,
# 调入显存的blocks
blocks_to_swap_in=swapped_in.blocks_to_swap_in,
# 调出显存的blocks
blocks_to_swap_out=running_scheduled.blocks_to_swap_out,
# 需要tokens并发生成的sg
blocks_to_copy=running_scheduled.blocks_to_copy +
swapped_in.blocks_to_copy,
# 设置为finished的sg
ignored_seq_groups=prefills.ignored_seq_groups +
swapped_in.infeasible_seq_groups,
# 槽位数
num_lookahead_slots=running_scheduled.num_lookahead_slots,
running_queue_size=len(self.running),
# 冻结的sg
preempted=(len(running_scheduled.preempted) +
len(running_scheduled.swapped_out)),
)
2.2 create sequence metadata
- 在得到SchedulerOutputs的结果后,我们对结果解包并做一些后处理,处理后的数据就是model_executor的输入了。
def schedule(
self
) -> Tuple[List[SequenceGroupMetadata], SchedulerOutputs, bool]:
scheduler_start_time = time.perf_counter()
# 调度获取所有输出的kv blocks
scheduler_outputs = self._schedule()
now = time.time()
if not self.cache_config.enable_prefix_caching:
common_computed_block_nums = []
allow_async_output_proc: bool = self.use_async_output_proc
# 根据调度sequence group创建对应meta data.
seq_group_metadata_list: List[SequenceGroupMetadata] = []
for i, scheduled_seq_group in enumerate(
scheduler_outputs.scheduled_seq_groups):
seq_group = scheduled_seq_group.seq_group
token_chunk_size = scheduled_seq_group.token_chunk_size
seq_group.maybe_set_first_scheduled_time(now)
# 清除上一次缓存中的数据
seq_group_metadata = self._seq_group_metadata_cache[
self.cache_id].get_object()
seq_group_metadata.seq_data.clear()
seq_group_metadata.block_tables.clear()
# seq_id -> SequenceData
seq_data: Dict[int, SequenceData] = {}
# 对于每一个sequence group都有一个block_tables
block_tables: Dict[int, List[int]] = {}
if seq_group.is_encoder_decoder():
# Encoder associated with SequenceGroup
encoder_seq = seq_group.get_encoder_seq()
assert encoder_seq is not None
encoder_seq_data = encoder_seq.data
# Block table for cross-attention
# Also managed at SequenceGroup level
cross_block_table = self.block_manager.get_cross_block_table(
seq_group)
else:
encoder_seq_data = None
cross_block_table = None
# 获取正在处于调度的tokens
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
seq_id = seq.seq_id
# 映射当前进行中的数据
seq_data[seq_id] = seq.data
# 映射当前进行中的tokens的block_table
block_tables[seq_id] = self.block_manager.get_block_table(seq)
# 更新block_manager中当前token的操作时间
self.block_manager.access_all_blocks_in_seq(seq, now)
# 对于前缀缓存,我们需要知道哪些token是存在前缀共享的
if self.cache_config.enable_prefix_caching:
common_computed_block_nums = (
self.block_manager.get_common_computed_block_ids(
seq_group.get_seqs(status=SequenceStatus.RUNNING)))
do_sample = True
is_prompt = seq_group.is_prefill()
# 我们需要在prefill阶段后发送metadata信息(chunked prefill / decode)
is_first_prefill = False
if is_prompt:
# 看所有的seqs是否存在计算
seqs = seq_group.get_seqs()
# Prefill has only 1 sequence.
assert len(seqs) == 1
num_computed_tokens = seqs[0].data.get_num_computed_tokens()
is_first_prefill = num_computed_tokens == 0
# 在所有prefill阶段(包括chunked prefill),不需要sample结果.
if (token_chunk_size + num_computed_tokens <
seqs[0].data.get_len()):
do_sample = False
# It assumes the scheduled_seq_groups is ordered by prefill < decoding.
# 只有在prefill中且非增量时,发送全部metadata,其他发送增量metadata
if is_first_prefill or not self.scheduler_config.send_delta_data:
seq_group_metadata = SequenceGroupMetadata(
request_id=seq_group.request_id,
is_prompt=is_prompt,
seq_data=seq_data,
sampling_params=seq_group.sampling_params,
block_tables=block_tables,
do_sample=do_sample,
pooling_params=seq_group.pooling_params,
token_chunk_size=token_chunk_size,
lora_request=seq_group.lora_request,
computed_block_nums=common_computed_block_nums,
encoder_seq_data=encoder_seq_data,
cross_block_table=cross_block_table,
state=seq_group.state,
# `multi_modal_data` will only be present for the 1st comm
# between engine and worker.
# the subsequent comms can still use delta, but
# `multi_modal_data` will be None.
multi_modal_data=seq_group.multi_modal_data
if scheduler_outputs.num_prefill_groups > 0 else None,
prompt_adapter_request=seq_group.prompt_adapter_request,
)
else:
# 当开启自动并行计算系统(分布式加速SPMD)功能后,我们在decode阶段只需要发送delta数据即可
seq_data_delta = {}
for id, data in seq_data.items():
seq_data_delta[id] = data.get_delta_and_reset()
seq_group_metadata = SequenceGroupMetadataDelta(
seq_data_delta,
seq_group.request_id,
block_tables,
is_prompt,
do_sample=do_sample,
token_chunk_size=token_chunk_size,
computed_block_nums=common_computed_block_nums,
)
seq_group_metadata_list.append(seq_group_metadata)
if allow_async_output_proc:
allow_async_output_proc = self._allow_async_output_proc(
seq_group)
# 现在batch已确定,我们可以假设batch中的所有块都会在下一次调度调用之前计算完毕。
# 这是因为引擎假设模型执行失败会导致vLLM实例崩溃/不会重试。 因此我们先标记这些block已计算
for scheduled_seq_group in scheduler_outputs.scheduled_seq_groups:
self.block_manager.mark_blocks_as_computed(
scheduled_seq_group.seq_group,
scheduled_seq_group.token_chunk_size)
self._seq_group_metadata_cache[self.next_cache_id].reset()
scheduler_time = time.perf_counter() - scheduler_start_time
# 将所有运行中的sg更新调度时间进度,方便统计.
for seq_group in self.running:
if seq_group is not None and seq_group.metrics is not None:
if seq_group.metrics.scheduler_time is not None:
seq_group.metrics.scheduler_time += scheduler_time
else:
seq_group.metrics.scheduler_time = scheduler_time
# 0/1 索引切换缓存区
self.cache_id = self.next_cache_id
# 返回sq_meta、scheduler outputs
return (seq_group_metadata_list, scheduler_outputs,
allow_async_output_proc)
3. Blockmanager
上文讲了调度的大致逻辑,和sg的一些后处理逻辑,那么具体我们是如何利用block_table分配物理block,如何判断目前block资源,这一部分都是在BlockManager中,这一节,我们会进一步抽象上面的逻辑,重点分析一下在Blockmanager内部各个阶段中,如何处理和分配block。vLLM提供了两个版本的Blockmana ger: BlockSpaceManagerV1 和 BlockSpaceManagerV2, V2是改进版本,目前还未完全开发完成,并且还不支持prefix caching。因此本节以介绍BlockSpaceManagerV1为主。
我们首先看一下构造函数
class BlockSpaceManagerV1(BlockSpaceManager):
def __init__(
self,
block_size: int,
num_gpu_blocks: int,
num_cpu_blocks: int,
watermark: float = 0.01,
sliding_window: Optional[int] = None,
enable_caching: bool = False,
) -> None:
# 一个block的token个数,默认16
self.block_size = block_size
# gpu分配的block个数
self.num_total_gpu_blocks = num_gpu_blocks
# cpu分配的block个数
self.num_total_cpu_blocks = num_cpu_blocks
if enable_caching and sliding_window is not None:
raise NotImplementedError(
"Sliding window is not allowed with prefix caching enabled!")
self.block_sliding_window = None
if sliding_window is not None:
# 滑动窗口的中的block大小
self.block_sliding_window = math.ceil(sliding_window / block_size)
# 水位90%
self.watermark = watermark
assert watermark >= 0.0
self.enable_caching = enable_caching
self.watermark_blocks = int(watermark * num_gpu_blocks)
if self.enable_caching:
# 开启前缀缓存的Block分配器
self.gpu_allocator: BlockAllocatorBase = CachedBlockAllocator(
Device.GPU, block_size, num_gpu_blocks)
self.cpu_allocator: BlockAllocatorBase = CachedBlockAllocator(
Device.CPU, block_size, num_cpu_blocks)
else:
self.gpu_allocator = UncachedBlockAllocator(
Device.GPU, block_size, num_gpu_blocks)
self.cpu_allocator = UncachedBlockAllocator(
Device.CPU, block_size, num_cpu_blocks)
# 每一个sequence对应一个BT
# Mapping: seq_id -> BlockTable.
self.block_tables: Dict[int, BlockTable] = {}
# 对encode-decode模型,存在cross-attention层,我们为这个层需要引入单独的KVCache表
# Mapping: req_id -> BlockTable
# Note that each SequenceGroup has a unique
# request ID
self.cross_block_tables: Dict[str, BlockTable] = {}
3.1 UncachedBlockAllocator
- 在UncachedBlockAllocator中,是不带prefix缓存的块分配器,我们先看一下在不同调度队列流程中的图解,对running队列,这里的can_allocate只是通过目前剩余的block数量是否满足
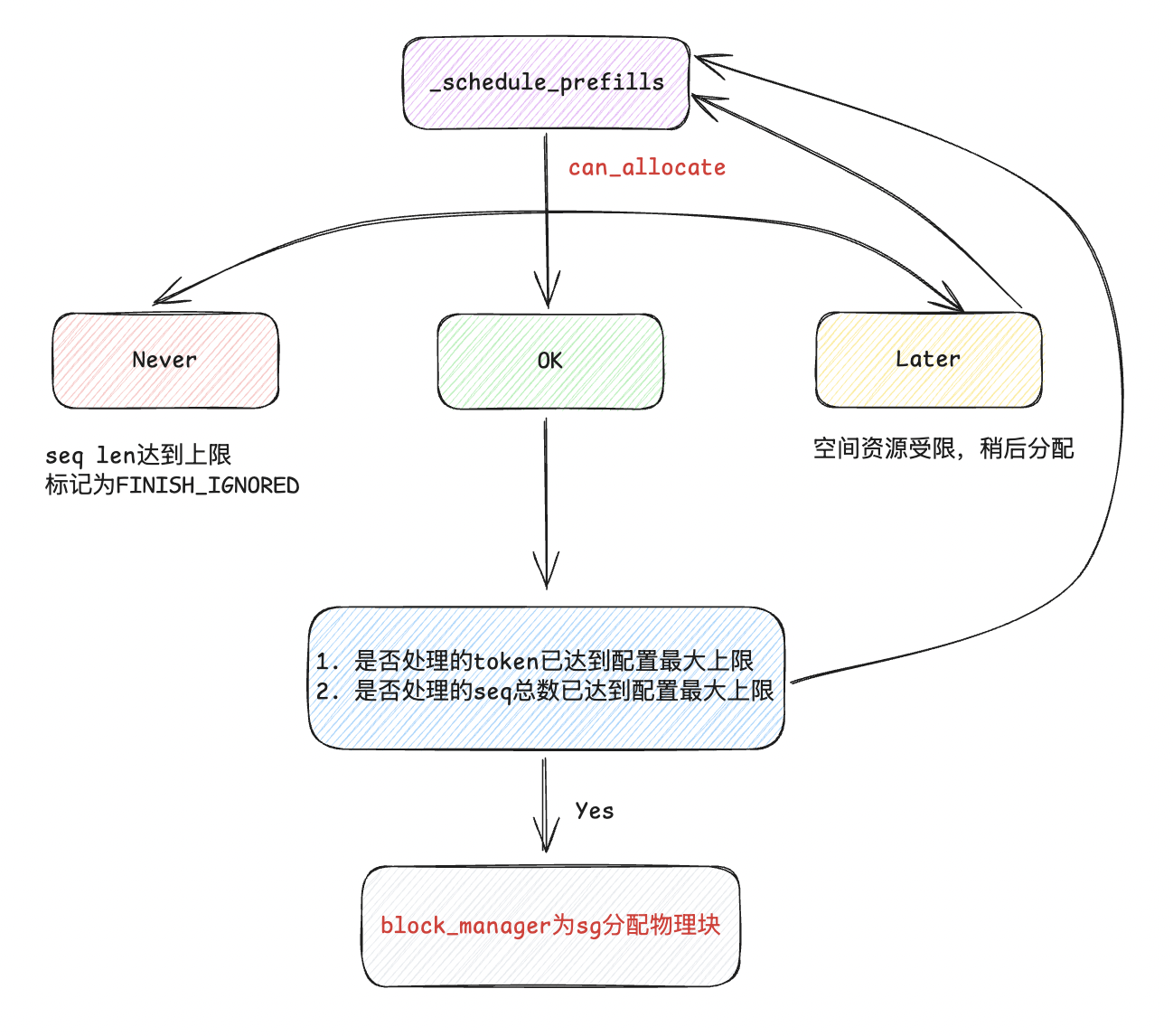
def can_allocate(self, seq_group: SequenceGroup) -> AllocStatus:
check_no_caching_or_swa_for_blockmgr_encdec(self, seq_group)
self_num_required_blocks = self._get_seq_num_required_blocks(
seq_group.get_seqs(status=SequenceStatus.WAITING)[0])
cross_num_required_blocks = self._get_seq_num_required_blocks(
seq_group.get_encoder_seq())
num_required_blocks = self_num_required_blocks + \
cross_num_required_blocks
if self.block_sliding_window is not None:
num_required_blocks = min(num_required_blocks,
self.block_sliding_window)
num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks()
# 所有block都不满足需求.
if (self.num_total_gpu_blocks - num_required_blocks <
self.watermark_blocks):
return AllocStatus.NEVER
# 剩余free满足,进行分配
if num_free_gpu_blocks - num_required_blocks >= self.watermark_blocks:
return AllocStatus.OK
else:
# 再等等
return AllocStatus.LATER
- 下面会真正的分配物理块号
def _allocate_sequence(self, seq: Optional[Sequence], ref_count: int, \
is_encoder_decoder: bool = True) -> BlockTable:
# 获得这个sequence需要多少个block.
num_prompt_blocks = self._get_seq_num_required_blocks(seq)
block_table: BlockTable = BlockTable()
assert seq is not None
# 每个逻辑块号从0开始
for logical_idx in range(num_prompt_blocks):
if (self.block_sliding_window is not None
and logical_idx >= self.block_sliding_window):
# 开启滑动窗口,重新映射逻辑块号id
block = block_table[logical_idx % self.block_sliding_window]
# Set the reference counts of the token blocks.
block.ref_count = ref_count
elif not is_encoder_decoder and self.enable_caching:
# 开启了前缀匹配
# hash值是对所有seq中的token进行整体hash,并将此值与驱逐器中进行比对
# 最终或者创建新的物理快,或者从驱逐器中回收物理块,返回使用
block = self.gpu_allocator.allocate(
seq.hash_of_block(logical_idx),
seq.num_hashed_tokens_of_block(logical_idx))
else:
# 直接从分配池中选取一个分配
block = self.gpu_allocator.allocate()
# Set the reference counts of the token blocks.
block.ref_count = ref_count
block_table.append(block)
return block_table
- waiting队列中的每个seq_group都还未经历过prefill阶段,因此每个seq_group下只有1个seq,这个seq即为prompt
- 在使用UncachedBlockAllocator为wating队列中的某个seq_group分配物理块时,我们就是在对初始的这个prompt分配物理块。所以这个prompt有多少个逻辑块,我们就分配多少个可用的空闲物理块,同时注意更新物理块的ref_count。
- 另外,这里给定一种“物理块的分配方案”,我们只是在制定这个seq_group可以使用哪些物理块,但并没有实际往物理块中添加数据。
- 具体物理块分配,由CacheEngine按照这个方案,往物理块中实际添加KVCache。这个我们留在再后面的模型执行的文章讲解。
上节主要说waitting阶段的块分配,主要面向prefill的数据,下面再看一下running/swaped队列中的分配逻辑,这里主要面对decode阶段的数据,这里主要用到了block_manager中的can_append_slots和append_slots两个方法。
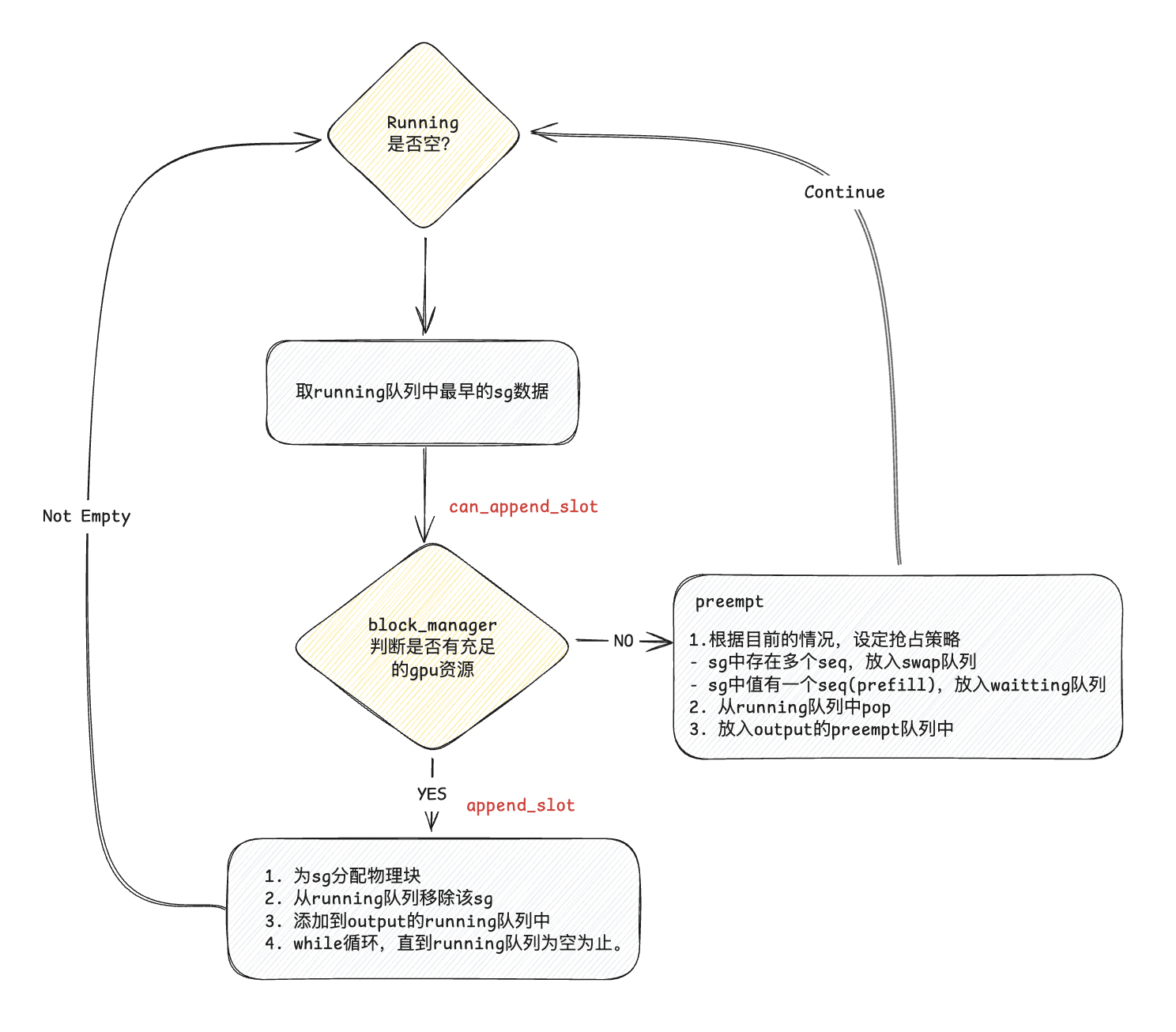
def can_append_slots(self, seq_group: SequenceGroup,
num_lookahead_slots: int = 0) -> bool:
assert (num_lookahead_slots == 0), "lookahead allocation not supported in BlockSpaceManagerV1"
# 就是看目前所有free的块是否满足running队列中需要的空间
num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks()
num_seqs = seq_group.num_seqs(status=SequenceStatus.RUNNING)
return num_seqs <= num_free_gpu_blocks
def append_slots(
self,
seq: Sequence,
num_lookahead_slots: int = 0,
) -> List[Tuple[int, int]]:
n_blocks = seq.n_blocks
block_table = self.block_tables[seq.seq_id]
# 查找block_table的物理块个数,看是否还有能力分配
# 如果物理块数量 < 逻辑块数量
if len(block_table) < n_blocks:
# 需要验证物理块只允许比逻辑块少1块
assert len(block_table) == n_blocks - 1
# 使用滑动窗口,做取整处理
if (self.block_sliding_window
and len(block_table) >= self.block_sliding_window):
# reuse a block
block_table.append(block_table[len(block_table) %
self.block_sliding_window])
else:
# 分配新物理块.
new_block = self._allocate_last_physical_block(seq)
block_table.append(new_block)
return []
# 如果最后一个物理块的引用数量为1, 也就是当前seq所引用
last_block = block_table[-1]
assert last_block.device == Device.GPU
if last_block.ref_count == 1:
# 如果开启前缀缓存,那么我们应该考虑物理块缓存问题.
if self.enable_caching:
# 当这个block已经填满是,我们需要在这里及时更新token hash,这有可能下次cache命中.
maybe_new_block = self._maybe_promote_last_block(
seq, last_block)
block_table[-1] = maybe_new_block
return []
else:
# 已经有其他sq使用了这table,我们需要.
# Copy on Write: Allocate a new block and copy the tokens.
new_block = self._allocate_last_physical_block(seq)
block_table[-1] = new_block
# 从该seq的block_table中释放掉旧的物理块
# 也即该物理块ref_count-=1,如果-=1后ref_count=0,说明该物理块彻底自由了,
# 然后可以把它添加进驱逐器的列表中,他将变为可缓存的自由块
self.gpu_allocator.free(last_block)
return [(last_block.block_number, new_block.block_number)]
3.2. CachedBlockAllocator(Prefix Caching)
- 在CachedBlockAllocator为有前缀缓存的Block分配器,会引入一个叫驱逐器(evictor)的概念,会将移除的KVCache数据在驱逐器中再保存一段时间,如果出现同样的前缀,再调度到GPU显存中。
3.2.1 驱逐器(evictor)
我们首先看一下evictor的实现,它使用access time和num_hashed_tokens确定我们优先需要使用哪个block进行重用。
class LRUEvictor(Evictor):
def __init__(self):
self.free_table: OrderedDict[int, PhysicalTokenBlock] = OrderedDict()
def __contains__(self, block_hash: int) -> bool:
return block_hash in self.free_table
def evict(self) -> PhysicalTokenBlock:
if len(self.free_table) == 0:
raise ValueError("No usable cache memory left")
evicted_block = next(iter(self.free_table.values()))
# 执行驱逐策略:
# 找到驱逐器free tables中last accessed time最早的那个物理块,把它驱逐掉,因为它已经很久没用了。
# 按理来说,free_tables中的物理块都是按时间append的,即已经排序好了,我们第1块即可。
# 但是若存在多个block的last_accessed一致,我们进行第二层判断
# 就先移除掉包含用于做hash的tokens最多的那个, 我们因此就挑选它作为GPU复用的块。
for _, block in self.free_table.items():
if evicted_block.last_accessed < block.last_accessed:
break
if evicted_block.num_hashed_tokens < block.num_hashed_tokens:
evicted_block = block
self.free_table.pop(evicted_block.block_hash)
# 此块的计算状态设为false
evicted_block.computed = False
# 返回这个缓存块
return evicted_block
def add(self, block: PhysicalTokenBlock):
self.free_table[block.block_hash] = block
def remove(self, block_hash: int) -> PhysicalTokenBlock:
if block_hash not in self.free_table:
raise ValueError(
"Attempting to remove block that's not in the evictor")
block: PhysicalTokenBlock = self.free_table[block_hash]
self.free_table.pop(block_hash)
return block
@property
def num_blocks(self) -> int:
return len(self.free_table)
3.2.2 prefix caching
- 当一个物理块没有任何逻辑块引用时(例如一个seq刚做完整个推理),这时它理应被释放。但是如果开启了prefix caching,那么这个物理块当前没有用武之地,但可是如果不久之后来了一个新seq,它的prefix和这个物理块指向一致,这个物理块就可以被重复使用,以此减少存储和计算开销。所以,我们设置一个驱逐器(evictor)类,它的free_tables属性将用于存放这些暂时不用的物理块。
- 所以目前,该设备上全部可用的物理块 = 正在被使用/等待被使用的物理块数量 + evictor的free_tables中的物理块数量
- 在prefill阶段,当我们想创建一个物理块时,我们先算出这个物理块的hash值,然后去free_tables中看有没有可以重复利用的物理块,有则直接复用
- 如果没有可以重复利用的hash块,那这时我们先检查下这台设备剩余的空间是否够我们创建一个新物理块。如果可以,就创建新物理块。
- 如果此时没有足够的空间创建新物理块,那么我们只好从free_tables中驱除掉一个物理块,为这个新的物理块腾出空间,驱逐策略如下:
- 先根据LRU(Least Recently Used)原则,驱逐较老的那个物理块,也就是上节说的access time
- 如果找到多个最后一次使用时间相同的老物理块,那么则根据max_num_tokens原则,驱逐其hash值计算中涵盖tokens最多的那个物理块。
- 如果这些老物理块的LRU和max_num_tokens还是一致的话,那就从它们中随机驱逐一个
我们可以通过下图理解这个prefix过程:
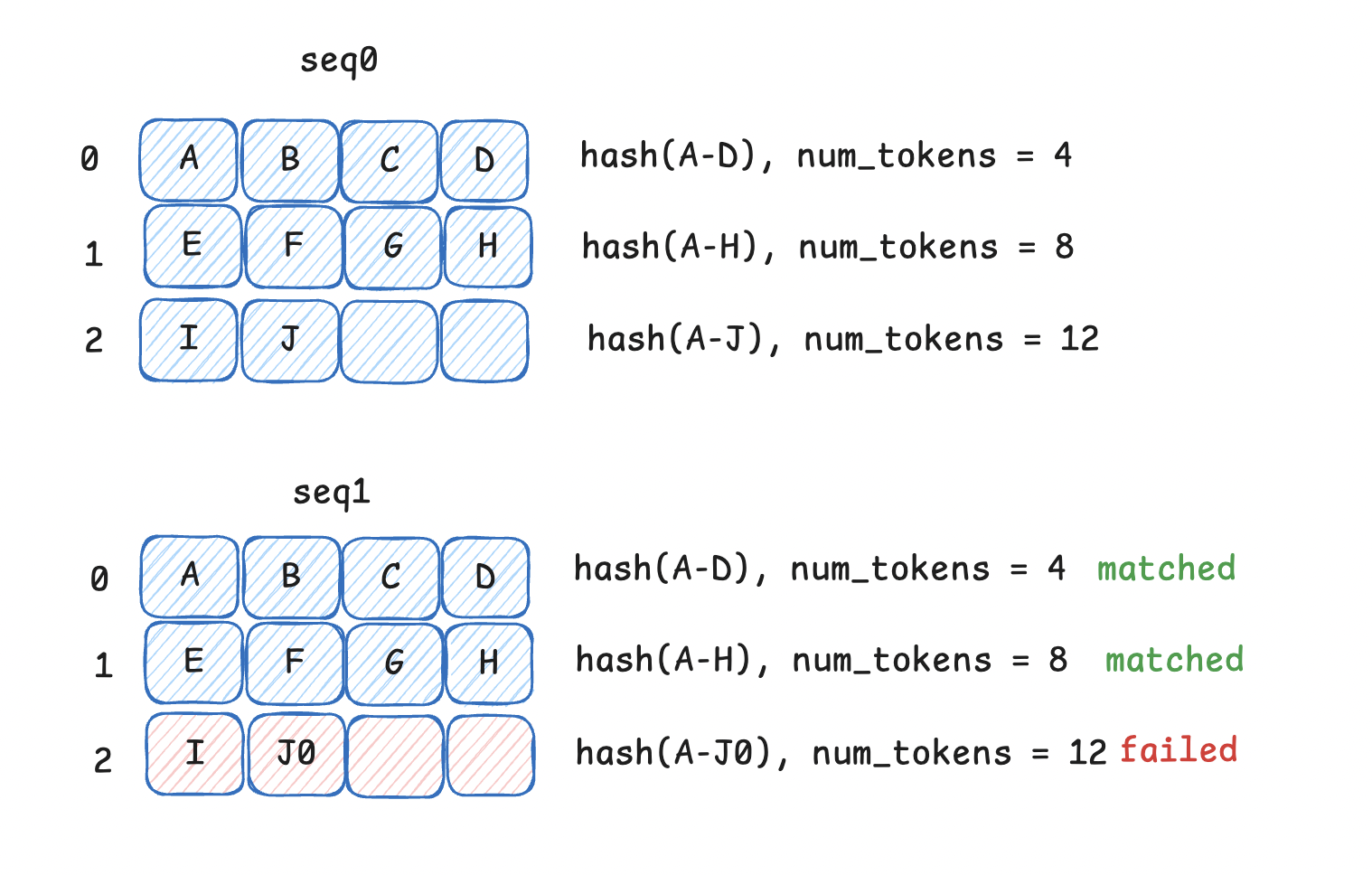
从图中我们可以看出,当已存在seq0时,我们已经收集了所有的hash结果。当seq1来时,需要在分配block时,我们会先看驱逐器中是否可以利用的hash, 存在就直接使用,不存在我们会为seq1再开辟一个新的block供其使用,放入对应的block_table中。
总结
本文对调度器的整体流程做了梳理,并对其成员BlockManager和BlockAllocator进行了拆解介绍。其中又详细分析了开启prefix caching后,引入驱逐器来提升物理块利用率。下篇文章讲针对模型执行器来进行分析,敬请期待。