- 图解vllm-原理与架构
- 图解vllm-推理服务与引擎
- 图解vllm-调度器与Block分配
- 图解vllm-执行器与worker
- 图解vllm-model之model和attention_backend
执行器(Executor)是对model worker的一层封装,LLMEngine会根据engine_config来创建确定创建哪个Executor,本文将以RayGPUExecutor为例进行介绍,Ray作为较为常用模型分布式框架,应用场景比较有代表性, 可以实现推理过程中的TP、PP并行推理。
1. Ray模型执行器图解
按源码中的举例,假设我们拥有两个节点、每个节点创建2个worker,每个worker使用2个GPU Device。Ray模型执行器整理交互框图如下:
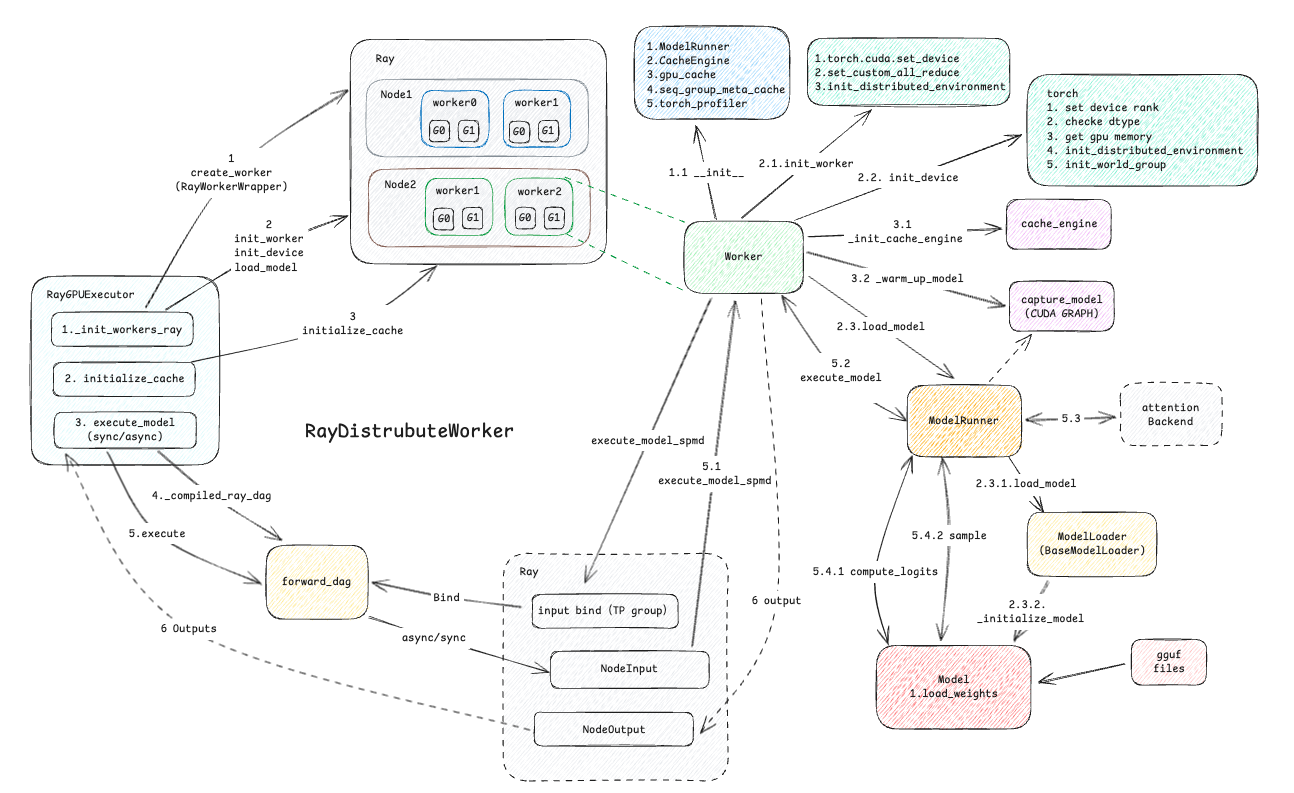
我们可以从图中看到几部分
- init_workers_ray: 初始化所有worker、device、environment、model等
- initialize_cache: 初始化分配KVCache空间
- execute_model: 输入execute_model_req(sync/async), 将请求传递给分布式worker,进行推理
接下来我也将按照这3部分来说明执行器的真个流程
2. Ray执行器流程串讲
我们首先看一下RayGPUExecutor的进程链, RayGPUExecutor->DistributedGPUExecutor->GPUExecutor->ExecutorBase->ABC。因此整体是基于DistributedGPUExecutor基础上对_init_executor、execute_model、_run_workers等几个关键方法进行了重写。
2.1 初始化执行器
- 线条1:执行器创建时会调用_init_executor进行初始化, 我们看一下代码:
def _init_executor(self) -> None:
self.forward_dag: Optional["ray.dag.CompiledDAG"] = None
# 此项是收集Ray服务拓扑,并向所有worker发送请求
self.use_ray_compiled_dag = envs.VLLM_USE_RAY_COMPILED_DAG
# 当开启拓扑后,我们创建worker有两个策略.
# 1. 区分driver_worker、remote_worker
# 2. use_ray_spmd_worker=True,不区分driver_worker,所有node都是remote_worker
self.use_ray_spmd_worker = envs.VLLM_USE_RAY_SPMD_WORKER
if self.use_ray_compiled_dag:
assert self.use_ray_spmd_worker, (
"VLLM_USE_RAY_COMPILED_DAG=1 requires "
"VLLM_USE_RAY_SPMD_WORKER=1")
if self.use_ray_spmd_worker:
# TODO: Support SPMD worker for non-DAG Ray executor.
assert self.use_ray_compiled_dag, (
"VLLM_USE_RAY_SPMD_WORKER=1 requires "
"VLLM_USE_RAY_COMPILED_DAG=1")
assert self.uses_ray
placement_group = self.parallel_config.placement_group
# Disable Ray usage stats collection.
ray_usage = os.environ.get("RAY_USAGE_STATS_ENABLED", "0")
if ray_usage != "1":
os.environ["RAY_USAGE_STATS_ENABLED"] = "0"
# 这里就是正式初始化worker的流程了.
self._init_workers_ray(placement_group)
# 初始化通信协议编解码器
self.input_encoder = msgspec.msgpack.Encoder(enc_hook=encode_hook)
self.output_decoder = msgspec.msgpack.Decoder(
Optional[List[SamplerOutput]])
- 从上文可以看出_init_workers_ray是我们创建worker的核心,看一下相关代码
def _init_workers_ray(self, placement_group: "PlacementGroup",
**ray_remote_kwargs):
# dummy worker 仅仅是资源占用,但是并不真正执行推理.
self.driver_dummy_worker: Optional[RayWorkerWrapper] = None
# 工作worker.
self.workers: List[RayWorkerWrapper] = []
# 这是个二位表格,外层是PP列表,那层是TP列表.
self.pp_tp_workers: List[List[RayWorkerWrapper]] = []
if self.parallel_config.ray_workers_use_nsight:
ray_remote_kwargs = self._configure_ray_workers_use_nsight(
ray_remote_kwargs)
logger.info("use_ray_spmd_worker: %s", self.use_ray_spmd_worker)
# Create the workers.
driver_ip = get_ip()
worker_wrapper_kwargs = self._get_worker_wrapper_args()
for bundle_id, bundle in enumerate(placement_group.bundle_specs):
if not bundle.get("GPU", 0):
continue
scheduling_strategy = PlacementGroupSchedulingStrategy(
placement_group=placement_group,
placement_group_capture_child_tasks=True,
placement_group_bundle_index=bundle_id,
)
# 调用远程RayWorkerWrapper创建worker实例
worker = ray.remote(
num_cpus=0,
num_gpus=num_gpus,
scheduling_strategy=scheduling_strategy,
**ray_remote_kwargs,
)(RayWorkerWrapper).remote(**worker_wrapper_kwargs)
if self.use_ray_spmd_worker:
self.workers.append(worker)
else:
# 区分driver worker, driver worker是每个TP Group中索引为0的worker
# 相同发送的请求,driver worker会自动广播到本组中其他worker执行。
worker_ip = ray.get(worker.get_node_ip.remote())
if worker_ip == driver_ip and self.driver_dummy_worker is None:
# If the worker is on the same node as the driver, we use it
# as the resource holder for the driver process.
self.driver_dummy_worker = worker
self.driver_worker = RayWorkerWrapper(
**worker_wrapper_kwargs)
else:
# Else, added to the list of workers.
self.workers.append(worker)
# ................
# 检查node是否上线,并获取gpu id
worker_node_and_gpu_ids = self._run_workers("get_node_and_gpu_ids",
use_dummy_driver=True)
node_workers = defaultdict(list) # node id -> list of worker ranks
node_gpus = defaultdict(list) # node id -> list of gpu ids
# if we have a group of size 4 across two nodes:
# Process | Node | Rank | Local Rank | Rank in Group
# 0 | 0 | 0 | 0 | 0
# 1 | 0 | 1 | 1 | 1
# 2 | 1 | 2 | 0 | 2
# 3 | 1 | 3 | 1 | 3
for i, (node_id, gpu_ids) in enumerate(worker_node_and_gpu_ids):
node_workers[node_id].append(i)
gpu_ids = [int(x) for x in gpu_ids]
node_gpus[node_id].extend(gpu_ids)
for node_id, gpu_ids in node_gpus.items():
node_gpus[node_id] = sorted(gpu_ids)
all_ips = set(worker_ips + [driver_ip])
n_ips = len(all_ips)
n_nodes = len(node_workers)
VLLM_INSTANCE_ID = get_vllm_instance_id()
# 广播环境变量
self._run_workers("update_environment_variables",
all_args=self._get_env_vars_to_be_updated())
# 分布式同步端口号
distributed_init_method = get_distributed_init_method(
driver_ip, get_open_port())
# Initialize the actual workers inside worker wrapper.
init_worker_all_kwargs = [
self._get_worker_kwargs(
local_rank=node_workers[node_id].index(rank),
rank=rank,
distributed_init_method=distributed_init_method,
) for rank, (node_id, _) in enumerate(worker_node_and_gpu_ids)
]
# 传入参数,远程创建worker实例
self._run_workers("init_worker", all_kwargs=init_worker_all_kwargs)
# 初始化硬件设备、分组等
self._run_workers("init_device")
# 加载模型等
self._run_workers("load_model",
max_concurrent_workers=self.parallel_config.
max_parallel_loading_workers)
if self.use_ray_spmd_worker:
# 只有在use_ray_spmd_worker情况下,才构建pp_tp_workers列表
# 推理的时候,这会向所有self.pp_tp_workers直接广播请求
for pp_rank in range(self.parallel_config.pipeline_parallel_size):
self.pp_tp_workers.append([])
for tp_rank in range(
self.parallel_config.tensor_parallel_size):
# PP=2, TP=4
# pp_tp_workers = [[0, 1, 2, 3], [4, 5, 6, 7]]
rank = (pp_rank * self.parallel_config.tensor_parallel_size
) + tp_rank
assert len(self.pp_tp_workers[pp_rank]) == tp_rank
assert pp_rank < len(self.pp_tp_workers)
self.pp_tp_workers[pp_rank].append(self.workers[rank])
# self.tp_driver_workers只有在异步的模型执行时才会使用
# 由TP Group自动传播推理请求
self.tp_driver_workers: List[RayWorkerWrapper] = []
self.non_driver_workers: List[RayWorkerWrapper] = []
# Enforce rank order for correct rank to return final output.
for index, worker in enumerate(self.workers):
# The driver worker is rank 0 and not in self.workers.
rank = index + 1
if rank % self.parallel_config.tensor_parallel_size == 0:
self.tp_driver_workers.append(worker)
else:
self.non_driver_workers.append(worker)
- 线条1.1:远程Worker会通过创建RayWorkerWrapper实例的情况下进行worker的创建准备,并且初始化必要的组件
class RayWorkerWrapper(WorkerWrapperBase):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
# torch.cuda.set_device 设备初始化后,此项设置为true
self.compiled_dag_cuda_device_set = False
# 接收端编解码器
self.input_decoder = msgspec.msgpack.Decoder(ExecuteModelRequest,
dec_hook=decode_hook)
self.output_encoder = msgspec.msgpack.Encoder(enc_hook=encode_hook)
def execute_model_spmd(self, req_or_tuple: Union[bytes, Tuple[bytes, Optional[IntermediateTensors]]]
) -> bytes:
if isinstance(req_or_tuple, bytes):
serialized_req, intermediate_tensors = req_or_tuple, None
else:
serialized_req, intermediate_tensors = req_or_tuple
# 反序列化请求
execute_model_req = self.input_decoder.decode(serialized_req)
import torch
if not self.compiled_dag_cuda_device_set:
torch.cuda.set_device(self.worker.device)
self.compiled_dag_cuda_device_set = True
# 具体执行方法_execute_model_spmd
output = self.worker._execute_model_spmd(execute_model_req,
intermediate_tensors)
# Pipeline model request and output to the next pipeline stage.
if isinstance(output, IntermediateTensors):
output = serialized_req, output
else:
output = self.output_encoder.encode(output)
return output
- 在收集完所有配置信息并,上述worker实例已经创建完毕后,那么我们就开始实例化worker
# 传入参数,远程创建worker实例
self._run_workers("init_worker", all_kwargs=init_worker_all_kwargs)
# 初始化硬件设备、分组等
self._run_workers("init_device")
# 加载模型等
self._run_workers("load_model",
max_concurrent_workers=self.parallel_config.
max_parallel_loading_workers)
线条2.1: 下面看看WorkerWrapperBase中的init_worker方法
def init_worker(self, *args, **kwargs):
enable_trace_function_call_for_thread()
# see https://github.com/NVIDIA/nccl/issues/1234
os.environ['NCCL_CUMEM_ENABLE'] = '0'
from vllm.plugins import load_general_plugins
load_general_plugins()
if self.worker_class_fn:
worker_class = self.worker_class_fn()
else:
mod = importlib.import_module(self.worker_module_name)
worker_class = getattr(mod, self.worker_class_name)
# 具体实例化worker
self.worker = worker_class(*args, **kwargs)
assert self.worker is not None
class Worker(LocalOrDistributedWorkerBase):
def __init__(...) -> None:
# config needed
self.model_config = model_config
self.parallel_config = parallel_config
self.parallel_config.rank = rank
self.scheduler_config = scheduler_config
self.device_config = device_config
self.cache_config = cache_config
self.local_rank = local_rank
self.rank = rank
self.distributed_init_method = distributed_init_method
self.lora_config = lora_config
self.load_config = load_config
self.prompt_adapter_config = prompt_adapter_config
self.is_driver_worker = is_driver_worker
if parallel_config and is_driver_worker:
assert rank % parallel_config.tensor_parallel_size == 0, \
"Driver worker should be rank 0 of tensor parallel group."
if self.model_config.trust_remote_code:
# note: lazy import to avoid importing torch before initializing
from vllm.utils import init_cached_hf_modules
init_cached_hf_modules()
self.observability_config = observability_config
# Return hidden states from target model if the draft model is an
# mlp_speculator
speculative_args = {} if speculative_config is None \
or (speculative_config.draft_model_config.model ==
model_config.model) \
or (speculative_config.draft_model_config.hf_config.model_type
not in ["medusa", "mlp_speculator", "eagle"]) \
else {"return_hidden_states": True}
# 默认使用ModelRunner
ModelRunnerClass: Type[GPUModelRunnerBase] = ModelRunner
if model_runner_cls is not None:
ModelRunnerClass = model_runner_cls
elif self._is_embedding_model():
ModelRunnerClass = EmbeddingModelRunner
elif self._is_encoder_decoder_model():
ModelRunnerClass = EncoderDecoderModelRunner
# 创建runner
self.model_runner: GPUModelRunnerBase = ModelRunnerClass(
model_config,
parallel_config,
scheduler_config,
device_config,
cache_config,
load_config=load_config,
lora_config=self.lora_config,
kv_cache_dtype=self.cache_config.cache_dtype,
is_driver_worker=is_driver_worker,
prompt_adapter_config=prompt_adapter_config,
observability_config=observability_config,
**speculative_args,
)
# 稍后初始化cache_engine
self.cache_engine: List[CacheEngine]
# Initialize gpu_cache as embedding models don't initialize kv_caches
self.gpu_cache: Optional[List[List[torch.Tensor]]] = None
self._seq_group_metadata_cache: Dict[str, SequenceGroupMetadata] = {}
# Torch profiler. Enabled and configured through env vars:
# VLLM_TORCH_PROFILER_DIR=/path/to/save/trace
if envs.VLLM_TORCH_PROFILER_DIR:
torch_profiler_trace_dir = envs.VLLM_TORCH_PROFILER_DIR
logger.info("Profiling enabled. Traces will be saved to: %s",
torch_profiler_trace_dir)
# 创建profiler采集
self.profiler = torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
with_stack=True,
on_trace_ready=torch.profiler.tensorboard_trace_handler(
torch_profiler_trace_dir, use_gzip=True))
else:
self.profiler = None
线条2.2: 创建worker后,继续调用init_device方法
def init_device(self) -> None:
if self.device_config.device.type == "cuda":
# torch.distributed.all_reduce 不到同步点的时候不会释放内存. 因此内存会持续增长
# 我们默认关闭这个设置,保证内存相对稳定
# https://discuss.pytorch.org/t/cuda-allocation-lifetime-for-inputs-to-distributed-all-reduce/191573
os.environ["TORCH_NCCL_AVOID_RECORD_STREAMS"] = "1"
# This env var set by Ray causes exceptions with graph building.
os.environ.pop("NCCL_ASYNC_ERROR_HANDLING", None)
self.device = torch.device(f"cuda:{self.local_rank}")
torch.cuda.set_device(self.device)
# 清空内存
_check_if_gpu_supports_dtype(self.model_config.dtype)
gc.collect()
torch.cuda.empty_cache()
self.init_gpu_memory = torch.cuda.mem_get_info()[0]
else:
raise RuntimeError(
f"Not support device type: {self.device_config.device}")
# Initialize the distributed environment.
# 主要进行set_custom_all_reduce、init_distributed_environment、ensure_model_parallel_initialized三项操作
init_worker_distributed_environment(self.parallel_config, self.rank,
self.distributed_init_method,
self.local_rank)
# Set random seed.
set_random_seed(self.model_config.seed)
初始化设备时主要是进行下面三个操作:
- set_custom_all_reduce: 设置全局_ENABLE_CUSTOM_ALL_REDUCE环境变量
- init_distributed_environment: 利用torch分布式探测方法get_world_size(), 初始化并创建分布式分组
- ensure_model_parallel_initialized: 建立PP、TP模型组,方便后面执行execute_model,直接向GPU组灌输数据。
线条2.3: 初始化完设备后,我们进行模型的加载load_model
# 在vllm/worker/worker.py中,其实就是调用runner的load_model
def load_model(self):
self.model_runner.load_model()
# 我们先看一下runner的创建
class GPUModelRunnerBase(ModelRunnerBase[TModelInputForGPU]):
"""
Helper class for shared methods between GPU model runners.
"""
_model_input_cls: Type[TModelInputForGPU]
_builder_cls: Type[ModelInputForGPUBuilder]
def __init__(self, ...):
# 配置文件
self.model_config = model_config
self.parallel_config = parallel_config
self.scheduler_config = scheduler_config
self.device_config = device_config
self.cache_config = cache_config
self.lora_config = lora_config
self.load_config = load_config
self.is_driver_worker = is_driver_worker
self.prompt_adapter_config = prompt_adapter_config
self.return_hidden_states = return_hidden_states
self.observability_config = observability_config
self.device = self.device_config.device
self.pin_memory = is_pin_memory_available()
self.kv_cache_dtype = kv_cache_dtype
self.sliding_window = model_config.get_sliding_window()
self.block_size = cache_config.block_size
self.max_seq_len_to_capture = self.model_config.max_seq_len_to_capture
self.max_batchsize_to_capture = _get_max_graph_batch_size(
self.scheduler_config.max_num_seqs)
# 对不同的PP线,创建不同的runner
self.graph_runners: List[Dict[int, CUDAGraphRunner]] = [
{} for _ in range(self.parallel_config.pipeline_parallel_size)
]
self.graph_memory_pool: Optional[Tuple[
int, int]] = None # Set during graph capture.
self.has_seqlen_agnostic = model_config.contains_seqlen_agnostic_layers(
parallel_config)
# When using CUDA graph, the input block tables must be padded to
# max_seq_len_to_capture. However, creating the block table in
# Python can be expensive. To optimize this, we cache the block table
# in numpy and only copy the actual input content at every iteration.
# The shape of the cached block table will be
# (max batch size to capture, max context len to capture / block size).
self.graph_block_tables = np.zeros(
(self.max_batchsize_to_capture, self.get_max_block_per_batch()),
dtype=np.int32)
# atten head size
num_attn_heads = self.model_config.get_num_attention_heads(
self.parallel_config)
# attention后端,这个后文详细讲
self.attn_backend = get_attn_backend(
num_attn_heads,
self.model_config.get_head_size(),
self.model_config.get_num_kv_heads(self.parallel_config),
self.model_config.get_sliding_window(),
self.model_config.dtype,
self.kv_cache_dtype,
self.block_size,
) if num_attn_heads else None
if self.attn_backend:
# attention状态
self.attn_state = self.attn_backend.get_state_cls()(
weakref.proxy(self))
else:
self.attn_state = CommonAttentionState(weakref.proxy(self))
# Multi-modal data support
self.input_registry = input_registry
self.mm_registry = mm_registry
self.multi_modal_input_mapper = mm_registry \
.create_input_mapper(model_config)
self.mm_registry.init_mm_limits_per_prompt(self.model_config)
# Lazy initialization
self.model: nn.Module # Set after load_model
# Set after load_model.
self.lora_manager: Optional[LRUCacheWorkerLoRAManager] = None
self.prompt_adapter_manager: LRUCacheWorkerPromptAdapterManager = None
set_cpu_offload_max_bytes(
int(self.cache_config.cpu_offload_gb * 1024**3))
# Used to cache python objects
self.inter_data_cache: Dict[int, PyObjectCache] = {}
# 在 Pipeline-Parallel 中使用 PythonizationCache 会破坏 SequenceGroupToSample对象。
# 在 Pipeline-Parallel 中,我们有 1 个以上的 Scheduler,因此可能会连续调用 prepare_model_inputs()。
# 这会破坏缓存的 SequenceGroupToSample 对象,因为我们会在每次 prepare_model_inputs() 调用期间重置缓存.
self.sampling_metadata_cache: SamplingMetadataCache = \
SamplingMetadataCache() \
if self.parallel_config.pipeline_parallel_size == 1 else None
def load_model(self) -> None:
logger.info("Starting to load model %s...", self.model_config.model)
with DeviceMemoryProfiler() as m:
# 通过Model Registry找到模型路径,并动态加载
# 此方法会创建loader,并使用loader加载模型
self.model = get_model(model_config=self.model_config,
device_config=self.device_config,
load_config=self.load_config,
lora_config=self.lora_config,
parallel_config=self.parallel_config,
scheduler_config=self.scheduler_config,
cache_config=self.cache_config)
self.model_memory_usage = m.consumed_memory
logger.info("Loading model weights took %.4f GB",
self.model_memory_usage / float(2**30))
if self.prompt_adapter_config:
# Uses an LRU Cache. Every request, the requested
# prompt_adapters will be loaded (unless they are already loaded)
# and least recently used prompt_adapters will
# be unloaded if the cache is above capacity
self.prompt_adapter_manager = LRUCacheWorkerPromptAdapterManager(
self.scheduler_config.max_num_seqs,
self.scheduler_config.max_num_batched_tokens, self.device,
self.prompt_adapter_config)
self.model = (
self.prompt_adapter_manager.create_prompt_adapter_manager(
self.model))
if self.kv_cache_dtype == "fp8" and is_hip():
# 目前,只有 ROCm 通过 quantization_param_path 接受 kv-cache 缩放因子,
# 并且此功能将来会被弃用.
if self.model_config.quantization_param_path is not None:
if callable(getattr(self.model, "load_kv_cache_scales", None)):
warnings.warn(
"Loading kv cache scaling factor from JSON is "
"deprecated and will be removed. Please include "
"kv cache scaling factors in the model checkpoint.",
FutureWarning,
stacklevel=2)
# kv cache 量化
self.model.load_kv_cache_scales(
self.model_config.quantization_param_path)
logger.info("Loaded KV cache scaling factors from %s",
self.model_config.quantization_param_path)
else:
raise RuntimeError(
"Using FP8 KV cache and scaling factors provided but "
"model %s does not support loading scaling factors.",
self.model.__class__)
else:
logger.warning(
"Using FP8 KV cache but no scaling factors "
"provided. Defaulting to scaling factors of 1.0. "
"This may lead to less accurate results!")
if envs.VLLM_TEST_DYNAMO_GRAPH_CAPTURE and supports_dynamo():
from vllm.compilation.backends import vllm_backend
# vllm_backend 默认编译后端
from vllm.plugins import get_torch_compile_backend
backend = get_torch_compile_backend() or vllm_backend
# 创建模型
self.model = torch.compile(
self.model,
fullgraph=envs.VLLM_TEST_DYNAMO_FULLGRAPH_CAPTURE,
backend=backend)
3. 初始化KVCache
线条3.1: 在LLMEngine初始化的时候,我们会根据执行器获取的GPU、CPU存储大小,计算出block数量,然后初始化KVCache。调用initialize_cache方法进行cache初始化。最终这个请求会通过Ray传递给Worker。我们来看一下代码, 主要执行两个方法_init_cache_engine和_warm_up_model
def _init_cache_engine(self):
assert self.cache_config.num_gpu_blocks is not None
# 根据PP的大小,对每一个pipeline初始化一个CacheEngine
self.cache_engine = [
CacheEngine(self.cache_config, self.model_config,
self.parallel_config, self.device_config)
for _ in range(self.parallel_config.pipeline_parallel_size)
]
self.gpu_cache = [
# 取出gpu_cache方便使用
self.cache_engine[ve].gpu_cache
for ve in range(self.parallel_config.pipeline_parallel_size)
]
def _warm_up_model(self) -> None:
if not self.model_config.enforce_eager:
# 通过创建一个假数据初始化验证模型,并且执行cuda graph
self.model_runner.capture_model(self.gpu_cache)
# Reset the seed to ensure that the random state is not affected by
# the model initialization and profiling.
set_random_seed(self.model_config.seed)
线条3.2 了解大致逻辑后,我们来看一下CacheEngine的创建
class CacheEngine:
def __init__(
self,
cache_config: CacheConfig,
model_config: ModelConfig,
parallel_config: ParallelConfig,
device_config: DeviceConfig,
) -> None:
# 常规参数
self.cache_config = cache_config
self.model_config = model_config
self.parallel_config = parallel_config
self.device_config = device_config
self.head_size = model_config.get_head_size()
# Models like Jamba, have mixed typed layers, E.g Mamba
# 这里会根据pp配置,将层分段,分配给当前CacheEngine
self.num_attention_layers = model_config.get_num_attention_layers(
parallel_config)
# total_num_kv_heads // parallel_config.tensor_parallel_size
self.num_kv_heads = model_config.get_num_kv_heads(parallel_config)
self.block_size = cache_config.block_size
self.num_gpu_blocks = cache_config.num_gpu_blocks
if self.num_gpu_blocks:
self.num_gpu_blocks //= parallel_config.pipeline_parallel_size
self.num_cpu_blocks = cache_config.num_cpu_blocks
if self.num_cpu_blocks:
self.num_cpu_blocks //= parallel_config.pipeline_parallel_size
if cache_config.cache_dtype == "auto":
self.dtype = model_config.dtype
else:
self.dtype = STR_DTYPE_TO_TORCH_DTYPE[cache_config.cache_dtype]
# 或者attention backedn的部分
self.attn_backend = get_attn_backend(
model_config.get_num_attention_heads(parallel_config),
self.head_size,
self.num_kv_heads,
model_config.get_sliding_window(),
model_config.dtype,
cache_config.cache_dtype,
self.block_size,
)
# Initialize the cache.
# 根据num_gpu_blocks数量和设备类型分配
self.gpu_cache = self._allocate_kv_cache(
self.num_gpu_blocks, self.device_config.device_type)
self.cpu_cache = self._allocate_kv_cache(self.num_cpu_blocks, "cpu")
def _allocate_kv_cache(
self,
num_blocks: int,
device: str,
) -> List[torch.Tensor]:
"""Allocates KV cache on the specified device."""
# 直接使用attn_backend接口创建cache
kv_cache_shape = self.attn_backend.get_kv_cache_shape(
num_blocks, self.block_size, self.num_kv_heads, self.head_size)
pin_memory = is_pin_memory_available() if device == "cpu" else False
kv_cache: List[torch.Tensor] = []
for _ in range(self.num_attention_layers):
# null block in CpuGpuBlockAllocator requires at least that
# block to be zeroed-out.
# We zero-out everything for simplicity.
kv_cache.append(
torch.zeros(kv_cache_shape,
dtype=self.dtype,
pin_memory=pin_memory,
device=device))
return kv_cache
def swap_in(self, src_to_dst: torch.Tensor) -> None:
for i in range(self.num_attention_layers):
self.attn_backend.swap_blocks(self.cpu_cache[i], self.gpu_cache[i],
src_to_dst)
def swap_out(self, src_to_dst: torch.Tensor) -> None:
for i in range(self.num_attention_layers):
self.attn_backend.swap_blocks(self.gpu_cache[i], self.cpu_cache[i],
src_to_dst)
def copy(self, src_to_dsts: torch.Tensor) -> None:
self.attn_backend.copy_blocks(self.gpu_cache, src_to_dsts)
@staticmethod
def get_cache_block_size(
cache_config: CacheConfig,
model_config: ModelConfig,
parallel_config: ParallelConfig,
) -> int:
# FlashAttention supports only head_size 32, 64, 128, 256,
# we need to pad head_size 192 to 256
head_size = model_config.get_head_size()
# total_num_kv_heads // parallel_config.tensor_parallel_size
num_heads = model_config.get_num_kv_heads(parallel_config)
num_attention_layers = model_config.get_num_attention_layers(
parallel_config)
key_cache_block = cache_config.block_size * num_heads * head_size
value_cache_block = key_cache_block
total = num_attention_layers * (key_cache_block + value_cache_block)
if cache_config.cache_dtype == "auto":
dtype = model_config.dtype
else:
dtype = STR_DTYPE_TO_TORCH_DTYPE[cache_config.cache_dtype]
dtype_size = get_dtype_size(dtype)
# 缓存总大小, num_heads_for_current_cache为当前分块的heads数量
# KVCacheMemory = 2 * (batch_size * num_heads_for_current_cache * head_size) * num_layers * dtype_size
return dtype_size * total
4. 模型推理
- 线条4: 真正进行推理的时候到了,无论是同步和异步调用,我们最终都会通过执行器的execute_model方法,传递execute_model_req给model去推理。那么对于Ray框架,我们首先要关联分布式服务的入口和出口数据(4.1)。可以通过_compiled_ray_dag来实现
def _compiled_ray_dag(self, enable_asyncio: bool):
assert self.parallel_config.use_ray
self._check_ray_adag_installation()
from ray.dag import InputNode, MultiOutputNode
from ray.experimental.channel.torch_tensor_type import TorchTensorType
logger.info("VLLM_USE_RAY_COMPILED_DAG_NCCL_CHANNEL = %s",
envs.VLLM_USE_RAY_COMPILED_DAG_NCCL_CHANNEL)
with InputNode() as input_data:
# Example DAG: PP=2, TP=4
# (ExecuteModelReq, None) -> 0 -> (ExecuteModelReq, IntermediateOutput) -> 4 -> SamplerOutput # noqa: E501
# -> 1 -> (ExecuteModelReq, IntermediateOutput) -> 5 -> SamplerOutput # noqa: E501
# -> 2 -> (ExecuteModelReq, IntermediateOutput) -> 6 -> SamplerOutput # noqa: E501
# -> 3 -> (ExecuteModelReq, IntermediateOutput) -> 7 -> SamplerOutput # noqa: E501
# All workers in the first TP group will take in the
# ExecuteModelRequest as input.
outputs = [input_data for _ in self.pp_tp_workers[0]]
for pp_rank, tp_group in enumerate(self.pp_tp_workers):
# Each PP worker takes in the output of the previous PP worker,
# and the TP group executes in SPMD fashion.
# 对所有tp worker实体,绑定execute_model_spmd的输入和输出
outputs = [
worker.execute_model_spmd.
bind( # type: ignore[attr-defined]
outputs[i]) for i, worker in enumerate(tp_group)
]
last_pp_rank = len(self.pp_tp_workers) - 1
if pp_rank < last_pp_rank:
# Specify how intermediate tensors should be passed
# between pp stages, no need to specify for the last
# pp stage.
transport = "nccl" \
if envs.VLLM_USE_RAY_COMPILED_DAG_NCCL_CHANNEL \
else "auto"
# 使用nccl进行分发
outputs = [
output.with_type_hint(
TorchTensorType(transport=transport))
for output in outputs
]
# 绑定execute_model_spmd输出
forward_dag = MultiOutputNode(outputs)
return forward_dag.experimental_compile(enable_asyncio=enable_asyncio)
- 线条5: 执行请求转发, 这会通过Ray框架,直接调用worker中的execute_model_spmd方法(5.1),
def execute_model_spmd(
self, req_or_tuple: Union[bytes, Tuple[bytes, Optional[IntermediateTensors]]]
) -> bytes:
if isinstance(req_or_tuple, bytes):
serialized_req, intermediate_tensors = req_or_tuple, None
else:
serialized_req, intermediate_tensors = req_or_tuple
# 反序列化数据
execute_model_req = self.input_decoder.decode(serialized_req)
import torch
if not self.compiled_dag_cuda_device_set:
torch.cuda.set_device(self.worker.device)
self.compiled_dag_cuda_device_set = True
# 模型执行推理
output = self.worker._execute_model_spmd(execute_model_req,
intermediate_tensors)
# Pipeline model request and output to the next pipeline stage.
if isinstance(output, IntermediateTensors):
output = serialized_req, output
else:
output = self.output_encoder.encode(output)
return output
def _execute_model_spmd(
self,
execute_model_req: ExecuteModelRequest,
intermediate_tensors: Optional[IntermediateTensors] = None
) -> Optional[List[SamplerOutput]]:
assert execute_model_req is not None, (
"_execute_model_spmd() requires each worker to take in an "
"ExecuteModelRequest")
# 转换成worker输入
worker_input: WorkerInput = self.prepare_worker_input(
execute_model_req=execute_model_req)
# 预处理输入
model_input: ModelRunnerInputBase = (
self.model_runner.prepare_model_input(
execute_model_req.seq_group_metadata_list))
# 换入、换出、复制需要使用的KVCache
self.execute_worker(worker_input)
# If there is no input, we don't need to execute the model.
if worker_input.num_seq_groups == 0:
return []
kwargs = extract_previous_hidden_states(execute_model_req)
# 推理
return self.model_runner.execute_model(
model_input=model_input,
kv_caches=self.kv_cache[worker_input.virtual_engine]
if self.kv_cache is not None else None,
intermediate_tensors=intermediate_tensors,
**kwargs,
)
线条5.2 推理最终是调用runner的 execute_model, 那么我继续分析代码
@torch.inference_mode()
@dump_input_when_exception(exclude_args=[0], exclude_kwargs=["self"])
def execute_model(
self,
model_input: ModelInputForGPUWithSamplingMetadata,
kv_caches: List[torch.Tensor],
intermediate_tensors: Optional[IntermediateTensors] = None,
num_steps: int = 1,
) -> Optional[Union[List[SamplerOutput], IntermediateTensors]]:
if num_steps > 1:
raise ValueError("num_steps > 1 is not supported in ModelRunner")
if self.lora_config:
assert model_input.lora_requests is not None
assert model_input.lora_mapping is not None
self.set_active_loras(model_input.lora_requests,
model_input.lora_mapping)
if self.prompt_adapter_config:
assert model_input.prompt_adapter_requests is not None
assert model_input.prompt_adapter_mapping is not None
self.set_active_prompt_adapters(
model_input.prompt_adapter_requests,
model_input.prompt_adapter_mapping)
# cuda graph
# 调用vllm/attention/backends/flashinfer.py中的begin_forward
# 通过flashinfer库来执行begin_forward
self.attn_state.begin_forward(model_input)
# Currently cuda graph is only supported by the decode phase.
assert model_input.attn_metadata is not None
prefill_meta = model_input.attn_metadata.prefill_metadata
decode_meta = model_input.attn_metadata.decode_metadata
# TODO(andoorve): We can remove this once all
# virtual engines share the same kv cache.
virtual_engine = model_input.virtual_engine
if prefill_meta is None and decode_meta.use_cuda_graph:
assert model_input.input_tokens is not None
graph_batch_size = model_input.input_tokens.shape[0]
# 获得要执行的model backend
model_executable = self.graph_runners[virtual_engine][
graph_batch_size]
else:
model_executable = self.model
multi_modal_kwargs = model_input.multi_modal_kwargs or {}
seqlen_agnostic_kwargs = {
"finished_requests_ids": model_input.finished_requests_ids,
"request_ids_to_seq_ids": model_input.request_ids_to_seq_ids,
} if self.has_seqlen_agnostic else {}
# prefile统计
if (self.observability_config is not None
and self.observability_config.collect_model_forward_time):
model_forward_start = torch.cuda.Event(enable_timing=True)
model_forward_end = torch.cuda.Event(enable_timing=True)
model_forward_start.record()
# 真正执行cuda graph + data
# 执行model文件中的forward代码
hidden_or_intermediate_states = model_executable(
input_ids=model_input.input_tokens,
positions=model_input.input_positions,
kv_caches=kv_caches,
attn_metadata=model_input.attn_metadata,
intermediate_tensors=intermediate_tensors,
**MultiModalInputs.as_kwargs(multi_modal_kwargs,
device=self.device),
**seqlen_agnostic_kwargs)
if (self.observability_config is not None
and self.observability_config.collect_model_forward_time):
model_forward_end.record()
# Compute the logits in the last pipeline stage.
if not get_pp_group().is_last_rank:
if (self.is_driver_worker
and hidden_or_intermediate_states is not None
and isinstance(hidden_or_intermediate_states,
IntermediateTensors)
and self.observability_config is not None
and self.observability_config.collect_model_forward_time):
model_forward_end.synchronize()
model_forward_time = model_forward_start.elapsed_time(
model_forward_end)
orig_model_forward_time = 0.0
if intermediate_tensors is not None:
orig_model_forward_time = intermediate_tensors.tensors.get(
"model_forward_time", torch.tensor(0.0)).item()
hidden_or_intermediate_states.tensors["model_forward_time"] = (
torch.tensor(model_forward_time + orig_model_forward_time))
return hidden_or_intermediate_states
# 获得多层感知机的输出结果
logits = self.model.compute_logits(hidden_or_intermediate_states,
model_input.sampling_metadata)
if not self.is_driver_worker:
return []
if model_input.async_callback is not None:
model_input.async_callback()
# Sample the next token.
# 对logits根据采样配置进行采样
output: SamplerOutput = self.model.sample(
logits=logits,
sampling_metadata=model_input.sampling_metadata,
)
if (self.observability_config is not None
and self.observability_config.collect_model_forward_time
and output is not None):
model_forward_end.synchronize()
model_forward_time = model_forward_start.elapsed_time(
model_forward_end)
orig_model_forward_time = 0.0
if intermediate_tensors is not None:
orig_model_forward_time = intermediate_tensors.tensors.get(
"model_forward_time", torch.tensor(0.0)).item()
# If there are multiple workers, we are still tracking the latency
# from the start time of the driver worker to the end time of the
# driver worker. The model forward time will then end up covering
# the communication time as well.
output.model_forward_time = (orig_model_forward_time +
model_forward_time)
if self.return_hidden_states:
# we only need to pass hidden states of most recent token
assert model_input.sampling_metadata is not None
indices = model_input.sampling_metadata.selected_token_indices
if model_input.is_prompt:
hidden_states = hidden_or_intermediate_states.index_select(
0, indices)
output.prefill_hidden_states = hidden_or_intermediate_states
elif decode_meta.use_cuda_graph:
hidden_states = hidden_or_intermediate_states[:len(indices)]
else:
hidden_states = hidden_or_intermediate_states
output.hidden_states = hidden_states
# 返回结果
return [output]
5. 总结
以上就是整个模型执行器从创建、初始化、推理的大致过程,有很多细节本文是忽略的,但是大致流程通过图解可以清晰的表达。这里的attention backend、model加载后的方法绑定简单带过了,接下来的文章,会详细介绍这块的机制,补齐vllm图解的最后一段拼图,敬请期待。