Flyte 是一个面向机器学习、数据工程和分析工作流的云原生工作流编排平台。它由Lyft开发并开源,目前是Linux Foundation AI & Data下的一个孵化级项目。它的核心设计目标是让用户能够以 可复现、可扩展、类型安全 的方式定义、运行和管理复杂的数据/ML工作流。目前该项目已经可以进行生产级别的部署,并可支撑运行10000+级别的相关workflow任务。
1.组件与架构
flyte优势
flyte有如下一些业务特点,在用户可以很方便的使用,并且插件集丰富,可以轻松扩展到数据处理等其他任务。
| 特性 | 解释 |
|---|---|
| K8S原生运行 | 执行引擎基于K8S,所有任务都是pod运行,天然支持容器化和资源隔离,可大规模部署 |
| 易用的SDK | SDK(flytekit)通过简单的装饰函数@task、@workflow即可定义和串联起整个DAG,并可自定义ImageSpec、Container等运行时信息 |
| 自动缓存重试 | Flyte会通过任务hash计算对输出进行cache,避免重复计算,失败时可重试 |
| 版本及可视化 | 所有WF都会版本化,并通过flyte console页面进行可视化 |
| 丰富的插件集 | Flyte在SDK和后端服务都设计了可配置的插件系统,可以轻松运行Kubeflow、KubeRay、Kserve、Airflow、Argo、Dash等自系统任务 |
| 全生命周期 | 通过以上特性的组合,flyte支持了数据预处理、实验、训练、模型注册、推理等完整的ML生命周期跟踪 |
flyte模块分类
flyte整个项目由以下几个组件组成:
| 组件 | 用途 |
|---|---|
| FlyteKit | Python SDK,定义任务、工作流、Launch Plan等,当然也包括pyflyte,flytectl等命令行工具 |
| FlyteConsole | Web UI,支持查看任务、执行日志、版本、数据流图等 |
| FlyteAdmin | 控制平面(Control Plane),管理任务、工作流定义、执行记录、权限和调度、提交CRD等 |
| FlytePropeller | 数据平面(Data Plane),负责在Kubernetes上调度和执行工作流 DAG |
| FlyteScheduler | 定时任务触发器,支持周期性执行工作流(可选择性开启) |
| FlyteSnacks | Flyte 用户使用示例,包含了基础操作、插件使用样例 |
flyte整体架构图
flyte目前依赖postgres和minio两个公共服务用于存储数据,整体架构图如下
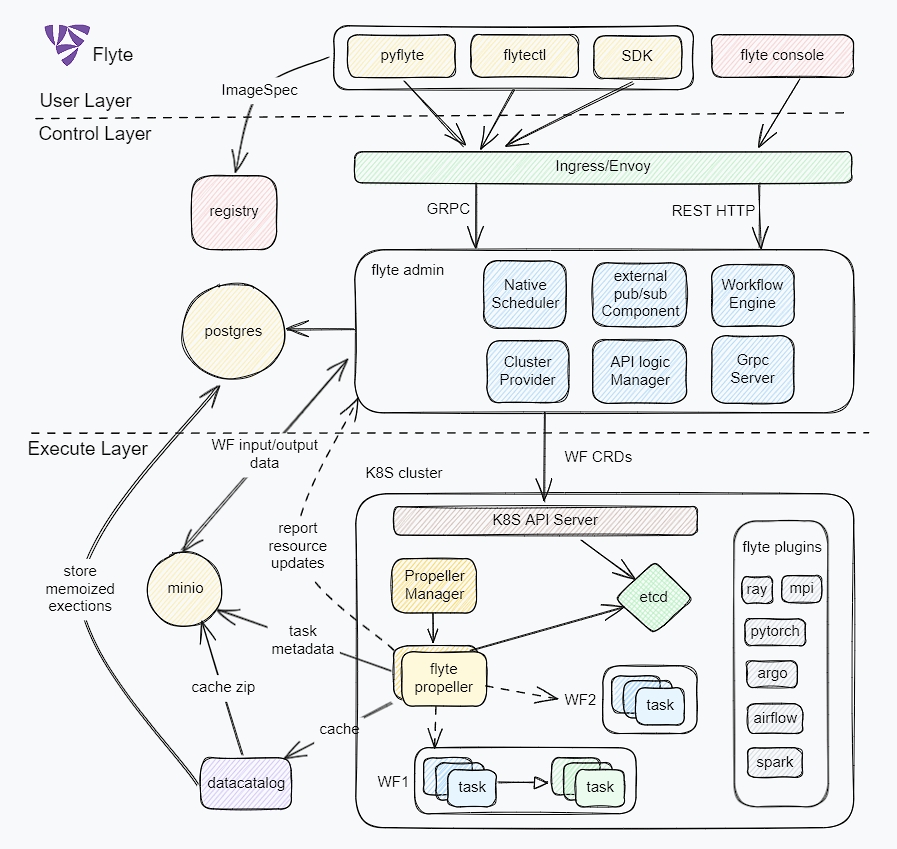
分层定义
-
用户层
flyte与用户交互入口,通过命令行、WebUI、SDK等工具提供工作流、运行任务、工作空间、插件组件的交互操作
- pyflyte:为在容器或者本地运行工作流的命令行工具, 面向开发者使用, 主要用途是运行workflow任务(local/remote)、构建镜像、pb构建、本地缓存管理、创建flyte模板项目、打包代码文件、创建运行计划等。
- flytectl:为与后端系统控制交互的命令行工具, 面向flyte平台管理运维者使用,主要用途是查看运行计划、执行实例、任务 运行状态、查看任务定义等。
- SDK:为用户提供灵活的task、workflow、imagespc、plugins的定义和组合,方便通过代码直接构建DAG,并与后端服务交互发起workflow。
-
控制层(admin)
为flyte的管理和调度中心,主要负责任务注册、自定义调度、执行状态管理、版本控制与权限治理等,其中主要组件有
- native scheduler: 主要负责调度用户定义的定时任务(LaunchPlan),即让工作流(Workflow)按照预设的 Cron表达式或固定间隔执行。
- auth: 内置了OAuth2授权服务器,即支持第三方的转发授权验证(适用于UI交互),也可以通过scope、client_id等方式对特定客户端进行授权验证(适用于组件间交互)。
- external pub/sub: 主要对内部系统和事件通知做管理,订阅propeller执行层的回调通知(node、workflow执行结果),并可将工作流的执行情况通过邮件、webhook地址等方式发送出去。
- workflow engin: 接入配置文件定义的k8s集群,并发送WF CRD, 同时也可以向CRD任务重注入上下文数据、label、annotation、event id等必要的关联和运行信息。
- cluster provider: 包括集群的资源、配置、执行队列、白名单、命名空间等资源的创建和管理
- API logic manager: 这部分承载API对应的业务逻辑,是db和各个执行模块的枢纽,包括计划任务、执行信息获取、节点执行管理、项目(团队任务)管理、工作流管理、任务信息等。
- Grpc server: 此部分是根据protobuf的定义生成的grpc服务代码和HTTP API相关协议的串联模块,其中也包括了trace设置、prometheus、log、https等环节的设置。
-
执行层(propeller)
负责执行workflow,调度其中task到不同的pod,并控制其生命周期和上报执行事件等功能、
-
plugins:通过插件机制,propeller可以接入和灵活发送任意后端请求,主要的插件有:
- K8s Plugin: 生成相应的 K8s CRD(Spark、MPIJob、TFJob、RayJob、Dask)
- Presto Plugin: 查询分布在多个系统中的大数据 (HDFS、Hive、S3、Mysql、Postgres、MongoDB、kafaka、ES等)
- webapi Plugin: 对接成熟的数据仓库子系统(bigquery、snowflake、databricks等)
- WF controller: 监听 FlyteWorkflow CRDs(由 Admin 下发),并调度执行节点,同时管理执行worker_pool,work_queue等并发组件,进行异步任务的并发执行。
- compiler: 将接收到的WF CRD进行分解,编译成node、task、branch、subworkflow等子任务,方便进行DAG调度
- Node executor: 负责单个节点(task/subworkflow/branch/gate)的执行
- Task Executor: 对task调用k8s API调度pod执行
- Event Recorder: 上报运行状态至admin(metrics + logs), 通过GRPC回传
- State Reconciler: controller核心功能,观察K8S CRD状态,并进行调和控制
- propeller manager(optional): 可以将flyte propeeler进行多实例部署,每个实例负责一类任务的处理,并用propeller manager进行统一管理,用户大规模任务的横向扩展
-
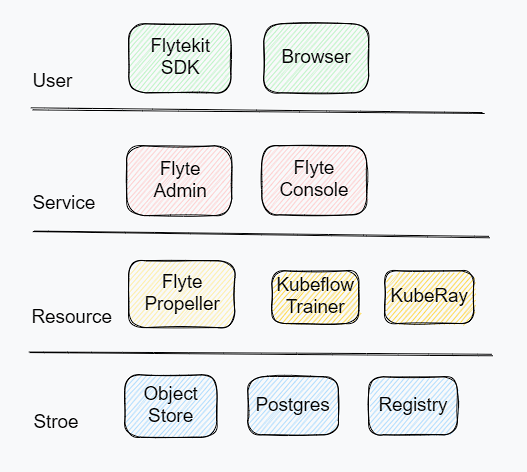
2.Flyte部署
从部署环境上看,分为用户层、服务层、资源层、存储层。
- 用户层通过SDK、浏览器与服务层进行交互、通信, 其中SDK还需要与镜像仓库交互,在启动任务前可创建自定义镜像, 并推送到镜像仓库中,需要部署到用户机器中。
- 服务层通过kubeconfig向各个算力集群中发送资源请求,同时将接收到的打包文件、执行记录写入DB中,需要部署在平台服务器机房。
- 资源层通过部署controller,并控制进群内部子服务(kubeflow、kuberay、spark)等系统,执行具体任务,并同步任务状态,需要部署到云厂商或者私有云集群当中。
- 存储层主要用于存储元数据、代码、任务缓存、镜像、服务记录等等,可以使用公共服务资源部署使用。
部署分层简图如下:
3.总结
本节通过整体架构简述了flyte使用的目标场景、分层架构,以及组件间的组成结构和关联关系,下一步将按flytekit、flytadmin、flytepropeller、catalog、datacopilot等详细的项目代码分析,方便想对其二次开发的用户找到切入点。