- RLinf图解-Framework 与 Single Controller
- RLinf图解-Channel 与 Worker 通信
- RLinf图解-Dynamic Scheduler
- RLinf图解-Workflow 与 Data
1. 背景
强化学习目前越来越多的应用在机器学习的各个方面: 大语言模型后训练、Agent 场景训练、VLA 训练等等。对于每种场景,强化学习遇到问题瓶颈侧重点各不相同。大体可以总结如下:
- 多角色共同参与,实时交互,数据交换量较大且动态
- 灵活的角色数量、资源需求,需要根据各种场景灵活配置,并且在运行时能动态扩缩调整,满足资源利用率情况。
- 角色间和角色内之间需要大量的通信,通信不应随着整体训练规模的增大成为瓶颈。
- 控制面和数据面并行,需要异步处理
- 由于 RL 在训练过程中需要与外部环境、系统实时做交互,所以需要存在整体流程控制管理、但对于数据层面处理需要子任务组进行分布式处理。
- 为了提高 GPU 利用率,控制面建立单独通信机制,并可异步处理,方便DP运行,减少训练过程中 GPU bubble 的产生。
2. 为什么需要 RL框架
2021 年Google 提出了Pathways 的分布式 AI系统概念,理论上讲述了我们的 AI 系统正从 SPMD 向 MPMD 方向转变.
- SPMD(Single Program Muli-Data): 单进程多数据场景,一个控制进程总体调度 worker组,并汇总 worker 结果。
- MPMD(Muti-Program Multi-Data): 多进程多数据场景,多个控制器需要相互配合,并且所属 worker 组在运行时阶段,需要根据实际情况灵活分配资源、扩缩容。
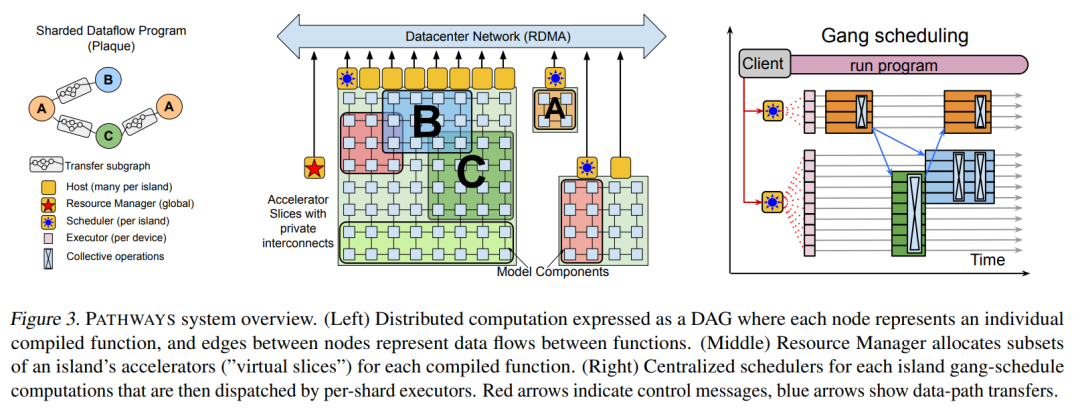
上图表示了 MPMD 的之间的逻辑关系。调度层面,需要整体workflow控制,达到 gang 调度的效果;资源层面,运行环境需要在异构集群中运行,可以动态绑定资源和调节规模。
根据MPMD 思想,在 RL 领域陆陆续续出现了针对不同场景的几个主流的训练框架。因此,使用一种基于 Single Control 思路做顶层 workflow 控制,简单说就是用一个进程控制分布式组 worker 进行集群处理,从而简化整体 workflow 的复杂度,组 worker通过 动态SPMD 形式执行 Multi-Data处理。
下表是各个框架的主打点对比:
| 框架 | RLinf | AReaL | Verl |
|---|---|---|---|
| 应用方向 | Embodiment | Agent | LLM |
| 数据分发特点 | P2P | Replay Buffer | FIFO Buffer |
| 目标模型 | VLA | LLM | LLM/VLM |
| 吞吐 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 适用场景 | 强交互环境 多模态输入 |
rollout 较长 吞吐优先 > 精度 |
精度优先 RLHF |
| 工业成熟度 | 无问芯穹 + 清华 | 蚂蚁 | 字节 |
- AReal 的特点是全异步化,并发和数据流并发非常高,但是在交互层面更多偏于 Agent 环境和工具的对接,强交互层支持较少,模型方面训练 LLM 为主。
- Verl更多专注于LLM 的后训练阶段,它采用了一个 FIFO 的消息总线来同步 worker 数据,随着规模增大,会出现一些数据吞吐量的性能下降,但是交叉验证控制和验证较好,训练精度高。
- Rlinf 更关注VLA 方向,并提供了 P2P 的通信机制,通过torch 的 distribution 包实现,在 RDMA 环境下,有更灵活和高效的通信效率,并且需要对与仿真环境实时进行交互,整体RLinf 更加适合。
整体来看在新一代主流的 RL 训练框架中,RLinf 更适合 VLA 和 交互性强的训练场景,AReal 其次,因此我们选择 RLinf 作为最终的训练框架方案,后续可将AReal的优秀特性移植到 RLinf 中,提升吞吐。
3. RLinf架构图
在了解如何使用之前,我们先整体理解一下 RLinf 架构,并分层分析,最后再进行不同场景组合配置。
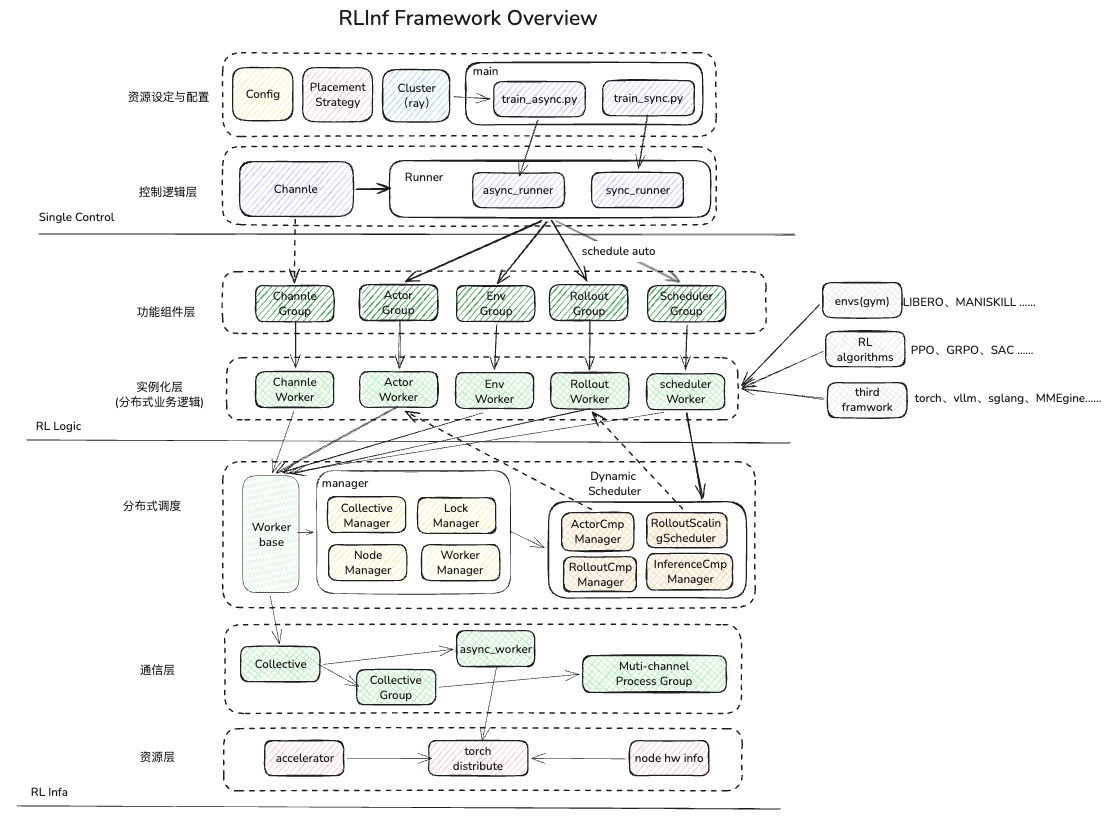
- 单点控制
- 资源设定与配置层为真题入口提供相关组件,分别为:
- Config:用于 RL 配置解析,使用omegaconf库,这个库的特点是可以对配置字段进行继承、合并、反序列化成 PyObject等,使用较为方便
- PlacementStrategy: 此模块会根据配置信息,对各个角色 worker 实例进行偏好性分配,可以进行集群随机分配(时序分配),也可以指定部分 gpu rank 分配(空间分配),同时也可以使用并行MP切分分配,用于 动态自适应分配(混合分配)
- Cluster: 重点是链接 ray 集群,获取 ray node 的信息和硬件信息,提供给 placement、worker、scheduler 进行查询信息使用。
- main 入口: 在主入口中,需要将以上组件初始化和组合起来,并传入控制逻辑 runner 中进行使用。主入口提供同步和异步模式,主要区别是在 channel 模式上,异步入口提供全异步的 channel 通信机制。
- 控制逻辑层:
- Channel: 是一种 channel worker 的顶层封装,主要提供异步和同步传送数据方法,并提供分布式 worker 的端侧部署,并通过 collective 维护不同 channel name 如何分发给不同的 worker 中。
- Runner: 此模块为逻辑调度使用,用户可以通过代码逻辑设定 worker 的调度顺序(针对时序分配、空间分配有效),也可以挂载动态调度器,进行(混合分配)动态扩缩调度。
- 资源设定与配置层为真题入口提供相关组件,分别为:
- RL 逻辑:
- Worker Group: 对于 SPMD 具体运行,是通过 Group 的概念进行封装实现的,Group 是 worker list 的封装,主要对 woker 进行初始化,并将 worker 注册到 worker manager 的单实例用中用于调度模块对 worker 的换入和换出。
-
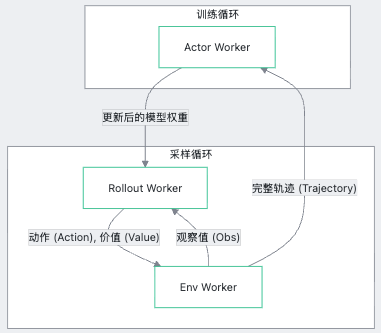
Role Woker: 对于在 RL中参与的各种角色和其逻辑,算法开发用户需要继承调度层的 Worker base 基类,用户只需关心该角色 worker 中的算法逻辑、交互实现、第三方训练、推理框架引入等,底层通信层面交由Worker base负责。在 RL 训练中一般集中角色之间的关系如下:
- RL 基础设施:
- 分布式调度:
- Worker Base: 此模块为调度的最小实例,本质上是 Ray Actor 的封账类,他负责把 Ray Actor 放置到相应的位置,并建立底层的 collective group,用于此 worker 对其他 worker 的P2P 通信,同时也将此 worker 信息,组信息注册到单实例的 Worker manager 中。
- Manager: 此模块为调度提供中心化的 worker 信息存储,调度会对 worker 进行操作后,维护相关manager 的信息。
- collective manger 用于通信拓扑维护
- Lock manager 用于应用设备、端口分配时的全局控制
- Node manager 用于保存 alive 的 node 信息
- worker manager 用于对注册的 worker 进行组分类管理,并提供worker 寻址能力,定位到具体的 node 和 ray actor 信息。
- Dynamic Scheduler: 此模块是在混合部署中自动化调度使用。传统的时序、空间部署,worker group 是整体执行结束后,在进行调度,我们需要很精细的调节 pipline 参数,并且这种参数是固化的,在一些场景下,反馈会降低 GPU 利用率。动态调度是通过设定阈值,当某一个 SPMD 进程组,达到完成阈值后,就开始下一个依赖 woker的调度,这样用户可以更灵活的配置流水线参数,无需关系因为流水线配置偏差,导致的 pipeline bubble 情况,从而能整体提升 GPU 利用率。
- 通信层:
- Collective为了 worker 实现 P2P通信的核心,他会将各个 endpoint 封装成 Multi-process Group,这个进程组会通过 worker的name 和 rank进行建立映射关系, 并且内部会持有 Async worker的异步方法用来对底层的 torch.distribution链接信息的维护。
- 资源层
- accelerator:用于对以后 GPU、实体机器人 进行适配,使用ray 的accelerrator 包对 NPU、NV_GPU、MUSA_GPU、AMD_GPU、INTEL_GPU 等主流设备进行适配。
- torch.distribute: 主要决定数据传输的模式,统一使用 tensor 进行序列化数据,对同类型的 GPU两端,使用 NCCL 进行通信;对于不同类型的 GPU/CPU两端,使用 GLOO 进行传输,再根据情况将数据 load 到GPU 显存中。
- node hw info: 主要提供 ray 节点中识别的 hw 信息,用于通信策略的设定。
- 分布式调度:
下一节,我们将具体解析每一层的具体实现,在分代码之前,我们先预设几个问题:
- 如何对不同的计算资源进行配置,并灵活分配的?
- worker之间和创建的channel 之间如何高效的通信的?
- RL 学习中各类角色worker的中心的 manager是如何工作的?
- 自动化的扩缩调度如何实现的?
4. 单点控制层解析
我们从程序入口 <examples/embodiment/train_async.py>开始说起,在 main 函数中,首先是进行集群的初始化 和 placement 的资源需求和分配进行设定。主要就是初始化集群信息、和组件进程
# 创建集群组件
cluster = Cluster(
cluster_cfg=cfg.cluster, distributed_log_dir=cfg.runner.per_worker_log_path
)
# 实例化一个混合组件放置策略对象 (HybridComponentPlacement) 。
component_placement = HybridComponentPlacement(cfg, cluster)
4.1 Cluster
先用一张简图描述了 cluster 模块做了哪些事情
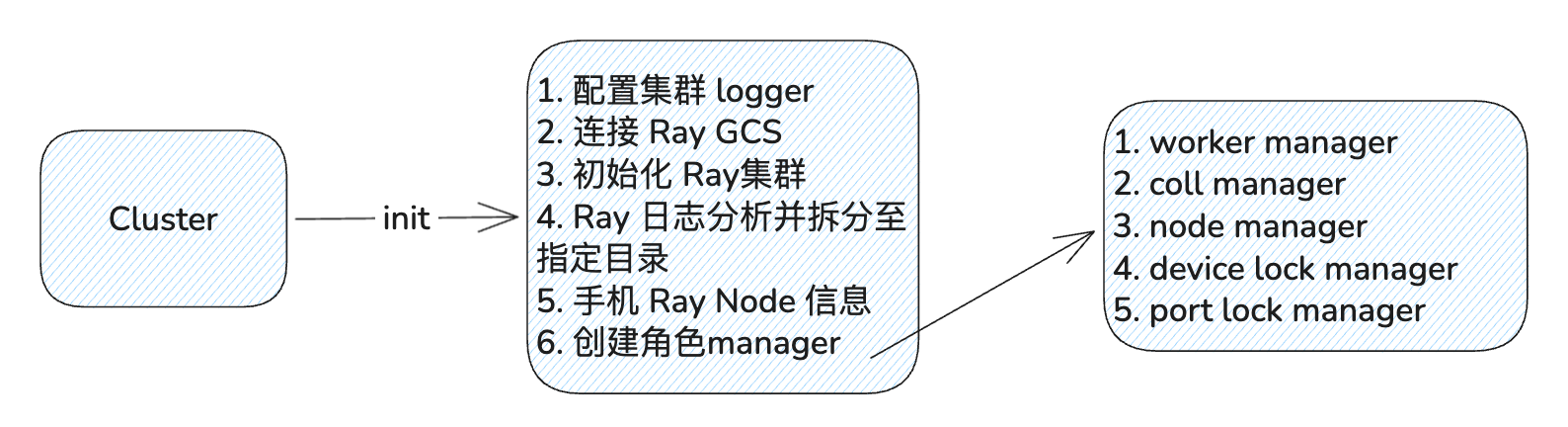
- 首先设置全局的 logger 策略,并指定日志输出的目录
- 然后在当前 ray 集群中自动探测 GCS header 节点地址,并连接
- 连接成功后,会初始化集群,验证集群版本和本地版本是否匹配,检查head是否正常运行等
- 收集 ray 的分布式集群输出日志,自动化收集、实时追踪与结构化分类
- 日志自动重定向与切分
- 按组归类 :它会根据 Worker 的组名(如 actor , rollout )在输出目录下创建子文件夹。
- 按 Rank 命名 :将原本杂乱的 Ray 日志文件名重新命名为 rank_0.log , rank_1.log 等。
- 结果路径 :最终生成的日志结构为
/ /rank_x.log 。
- 实时增量同步 (Tailing)
- 它在后台运行一个专用线程,以 poll_interval_s (默认 1 秒)为周期轮询 Ray 的原始日志文件。
- 通过维护 _file_offsets 字典,它能记住每个文件上次读取的位置,从而只同步增量内容。
- Ray 运行时 ID 解析
- 它利用 Ray 的内部 API( worker._global_node )获取集群的日志根目录。
- 通过resolve_registered_workers方法,查询到的 Actor中pid 和 node_id,进一步反查出 Ray 分配给该进程的唯一 worker_id。
- 然后 Ray 的日志文件遵循特定的命名规范: worker-{worker_id}-{job_id?}-{pid}.{out|err}, 因此就找到了具体进程的日志,并进行收集。
- 日志自动重定向与切分
- 收集 node 信息
# Get node info self._node_probe = NodeProbe(self._num_nodes, self._cluster_cfg) self._nodes = self._node_probe.nodes self._node_groups = self._node_probe.node_groups这里使用了一个NodeProbe类,它的核心作用是自动探测、收集并汇总 Ray 集群中每个物理节点的硬件资源和环境信息,为后期调度收集信息。
实现上,NodeProbe会在每个节点上创建_RemoteNodeProbe的 Actor 实例,并收集该 node 上信息: 节点的 IP 地址、CPU 核心数、Python 解释器路径以及预设的环境变量。
收集完所有信息后, NodeProbe 会在主进程中完成数据的汇总与分类:
- 生成 NodeInfo :为每个节点创建一个详细的 NodeInfo 对象。
- 划分 NodeGroup :根据用户在 YAML 中的配置( node_groups ),将物理节点归类到不同的逻辑组中(如“训练组”、“采样组”)等。
- 创建全局单实例managers,会启动五大核心管理器 :
- WorkerManager :
- 职责 :管理集群中所有 Worker 的生命周期、状态和元数据。它是 Worker 注册和查询的中心。
- CollectiveManager :
- 职责 :管理分布式集体通信(如 NCCL, Gloo)所需的资源。例如,协调不同进程组的端口分配和通信 ID 交换,在动态P2P 链路创建时,可会实时查询。
- NodeManager :
- 职责 :存储并提供集群中所有物理节点和节点组的信息。它持有了由 NodeProbe 探测到的 _nodes 和 _node_groups 原始数据。
- DeviceLockManager :
- 职责 : 硬件资源锁 。在多个任务或 Worker 同时申请同一块 GPU 时,它负责确保资源的互斥访问,防止分配资源冲突。
- PortLockManager :
- 职责 : 网络端口锁 。在分布式训练中(如设置 MASTER_PORT ),它负责协调并分配全局唯一的网络端口,用于通讯组交互端点信息使用。 Ray 可以 Acter name 可以快速查询到 manager 的引用,并调用远程方法获取数据。
- WorkerManager :
4.2 Component Placement
ComponentPlacement 类是 RLinf 调度系统中 最核心的组件布局定义类。它的核心作用是: 解析用户在配置文件(YAML)中定义的组件分布意图,并将其转化为一套底层的、可执行的硬件分配策略 。具有如下功能
- 资源校验 :在任务启动前,它会检查用户申请(配置)的 GPU 数量是否超出了集群实际拥有的资源。如果超出,会立即抛出清晰的错误。
- 确定性分配 :它确保了分布式训练的 可复现性 。相同的配置和集群环境,产生的组件布局始终是一致的。
- 异构支持 :它能够处理不同节点组(Node Groups)之间的差异。比如,它能自动识别出哪些节点组带有 A100,并将对应的组件引导到正确的机器上。
- 环境隔离配置 :它会为生成的每个 Placement 对象配置环境变量(CUDA_VISIBLE_DEVICES ),这是防止多进程资源抢占的关键, 从而只让角色 worker 看到他指定的设备。
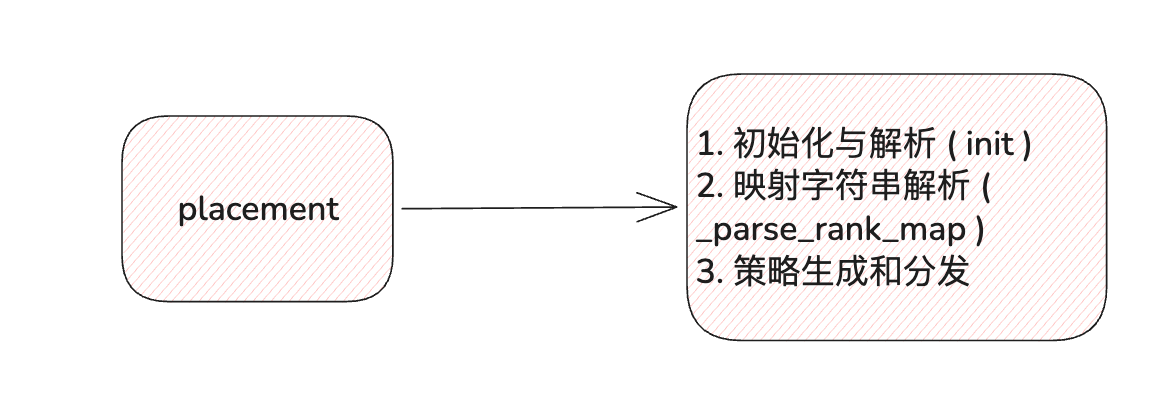
- 初始化与解析 ( init ) :
- 它接收 cfg (Hydra 配置)和 cluster (集群资源信息)作为输入。
- 提取配置 :它会从配置中找到 component_placement 节点。
- 多组件支持 :它可以同时管理多个组件(如 actor , rollout , env 等)。
- 映射字符串解析 ( _parse_rank_map ) :
- 它会解析类似于 0-7:0-7 这种字符串。
- 并且会利用 MultiNodeGroupResolver 确保这些 Rank 是合法的,并建立起“物理 GPU”与“逻辑 Worker 进程”之间的映射。
- 策略生成与分发 ( _gen_resource_placement / _gen_node_placement ) :
- FlexiblePlacementStrategy (GPU), 它允许你精确指定每个进程运行在哪些具体的硬件设备上。
- 具体表现 :
- 它可以实现 1:N (一个进程占用多个 GPU,如模型并行)。
- 它可以实现 N:1 (多个进程共享一个 GPU,如轻量级推理)。
- 修改CUDA_VISIBLE_DEVICES,让该进程只看到他的目标 GPU
- 代码逻辑 : 如 [[0, 1], [2]] ,表示第一个进程用 GPU 0 和 1,第二个进程用 GPU 2。
- 适用场景 :
- 训练(Actor):需要精确绑定 GPU 核心。
- 推理(Inference/Rollout):需要配置模型并行(TP/PP)。
- 具体表现 :
- NodePlacementStrategy (Node)
- 作用 :它只关心进程被分配到哪个 物理节点 上,而不关心该节点内部的硬件细节。
- 具体表现 :
- 它将整个节点视为一个单一资源,并且不修改CUDA_VISIBLE_DEVICES
- 代码逻辑 : 它接收一个简单的节点 Rank 列表,如 [0, 0, 1] ,表示前两个进程在 0 号节点,第三个在 1 号节点。
- 适用场景 :
- 纯 CPU 任务 :如 EnvWorker (环境模拟器)或某些数据预处理脚本。
- 无需 GPU 隔离的任务 :当你只需要确保进程分布在不同机器上,但不需要框架帮你管理显存隔离时。
- FlexiblePlacementStrategy (GPU), 它允许你精确指定每个进程运行在哪些具体的硬件设备上。
4.3 Runner
我们会根据配置、策略会引入不同的 runner(同步、异步), 不同的runner 在运行主逻辑的时候会有略微的差异。也可以引入异步和同步的 runner 用于调试,因为异步 runner 调试分析上更复杂。
入口代码中还有 worker group 的创建逻辑,创建不同的角色组实例,这部分我们放在下部分来解析。
if cfg.algorithm.loss_type == "embodied_sac":
from rlinf.runners.async_embodied_runner import AsyncEmbodiedRunner
from rlinf.workers.actor.async_fsdp_sac_policy_worker import (
AsyncEmbodiedSACFSDPPolicy,
)
runner_cls = AsyncEmbodiedRunner
actor_worker_cls = AsyncEmbodiedSACFSDPPolicy
elif cfg.algorithm.loss_type == "decoupled_actor_critic":
from rlinf.runners.async_ppo_embodied_runner import AsyncPPOEmbodiedRunner
from rlinf.workers.actor.async_ppo_fsdp_worker import AsyncPPOEmbodiedFSDPActor
runner_cls = AsyncPPOEmbodiedRunner
actor_worker_cls = AsyncPPOEmbodiedFSDPActor
# 创建 worker group, 稍后给出group 创建的逻辑
# .......
# 根据不同算法类型创建runner,并初始化worker,将 worker 部署到节点中,然后运行worker group调度(代码逻辑)
runner = runner_cls(
cfg=cfg,
actor=actor_group,
rollout=rollout_group,
env=env_group,
)
runner.init_workers()
runner.run()
- init: 函数会创建 channel、日志等对象。
- init_workers: 主要就是驱动 worker group 初始 worker,把 worker 按照规划放置到集群节点上 Ray Actor 实例化.
def __init__():
# ....
# worker 组间的 channel 实例
self.env_channel = Channel.create("Env")
self.rollout_channel = Channel.create("Rollout")
self.actor_channel = Channel.create("Actor")
# ....
# logger
self.logger = get_logger()
self.metric_logger = MetricLogger(cfg)
self.enable_per_worker_metric_log = bool(
self.cfg.runner.get("per_worker_log", False)
)
# ....
# Async logging setup
self.stop_logging = False
self.log_queue = queue.Queue()
self.log_thread = threading.Thread(target=self._log_worker, daemon=True)
self.log_thread.start()
def init_workers(self):
# 初始化 work group 中的 worker set
self.actor.init_worker().wait()
self.rollout.init_worker().wait()
self.env.init_worker().wait()
resume_dir = self.cfg.runner.get("resume_dir", None)
if resume_dir is None:
return
self.logger.info(f"Resuming training from checkpoint directory {resume_dir}.")
# 训练检查点路径,如何训练存在检查点的话
actor_checkpoint_path = os.path.join(resume_dir, "actor")
assert os.path.exists(actor_checkpoint_path), (
f"resume_dir {actor_checkpoint_path} does not exist."
)
self.actor.load_checkpoint(actor_checkpoint_path).wait()
self.global_step = int(resume_dir.split("global_step_")[-1])
- run: 执行时, RL主训练就开始启动了,这里的调度逻辑就是通过 run 的代码逻辑来整体驱动的,当然我们在 runner 中也可以指定更复杂的调度器类(后面动态调度的时候会分析),这样worker group 的调度可以交给调度器的策略来协调进行。我们先给出一个异步 runner 的代码示例,具体解析可以看注解部分。
'''
场景一:M=2 (Actor), N=8 (Rollout)
- rollout_ranks_per_actor = (8 + 2 - 1) // 2 = 4
- Actor 0 :
- i=0 : 0*2 + 0 = 0
- i=1 : 1*2 + 0 = 2
- i=2 : 2*2 + 0 = 4
- i=3 : 3*2 + 0 = 6
- 结果:负责同步给 Rollout [0, 2, 4, 6]
- Actor 1 :
- i=0 : 0*2 + 1 = 1
- i=1 : 1*2 + 1 = 3
- i=2 : 2*2 + 1 = 5
- i=3 : 3*2 + 1 = 7
- 结果:负责同步给 Rollout [1, 3, 5, 7]
场景二:M=4 (Actor), N=2 (Rollout)
- rollout_ranks_per_actor = (2 + 4 - 1) // 4 = 1
- Actor 0 : 负责 Rollout [0]
- Actor 1 : 负责 Rollout [1]
- Actor 2/3 : 不负责任何 Rollout(由于 target_rank < rollout_world_size 的判断)。
'''
def update_rollout_weights(self) -> None:
# rollout组等待接收,不同 rollout worker 一一对应不同的 actor worker
rollout_handle = self.rollout.sync_model_from_actor()
# actor组发起传送,同理不同 actor worker 一一对应不同的 rollout worker
self.actor.sync_model_to_rollout().wait()
rollout_handle.wait()
def run(self) -> None:
start_step = self.global_step
start_time = time.time()
self.actor.set_global_step(self.global_step).wait()
self.rollout.set_global_step(self.global_step).wait()
# 从actor同步model weight到 rollout,
# 这里落实到不同的 rollout 和 actor worker,他们会计算对方匹配的 worker rank 是多少,并发起同步亲够
# rollout 和 actor 是 N:M 关系,最终保证所有 rollout 都能单向同步到权重
self.update_rollout_weights()
# 通过人为定义 channel 的引用关系,设定组件之间的数据流动关系,从而驱动角色 worker 间的调度逻辑
# 此阶段 env通过调用interact方法 先向 rollout发送触发信号,rollout 进行推理,循环开始。
# 一轮batch rollout 结束后,env 会将 Trajectory 发送给 actor
env_handle: Handle = self.env.interact(
input_channel=self.rollout_channel,
output_channel=self.env_channel,
metric_channel=self.env_metric_channel,
replay_channel=self.actor_channel,
)
# rollout调用generate方法 在接收env 的反馈后,给出下一轮的action
rollout_handle: Handle = self.rollout.generate(
input_channel=self.env_channel,
output_channel=self.rollout_channel,
metric_channel=self.rollout_metric_channel,
)
# actor接收env 发送过来的轨迹,并进行训练
actor_handle: Handle = self.actor.recv_rollout_trajectories(
input_channel=self.replay_channel
)
while self.global_step < self.max_steps:
skip_step = False
with self.timer("step"):
# 此时,env 和 rollout 已经异步启动了震荡交互,并通过actor_channel驱动开始训练了
actor_training_handle: Handle = self.actor.run_training()
actor_result = actor_training_handle.wait()
if not actor_result[0]:
# 检查第一轮训练是否正常,如果不正常跳过次轮循环
skip_step = True
# 训练未完成
if not skip_step:
self.global_step += 1
if self.global_step % self.weight_sync_interval == 0:
# 定期更新
self.update_rollout_weights(no_wait=self.sync_weight_no_wait)
training_metrics = {
f"train/{k}": v
for k, v in self._aggregate_numeric_metrics(
actor_result
).items()
}
run_val, save_model, _ = check_progress(
self.global_step,
self.max_steps,
self.cfg.runner.val_check_interval,
self.cfg.runner.save_interval,
1.0,
run_time_exceeded=False,
)
if save_model:
self._save_checkpoint()
eval_metrics = {}
if run_val:
with self.timer("eval"):
eval_metrics = self.evaluate()
eval_metrics = {
f"eval/{k}": v for k, v in eval_metrics.items()
}
# 掉过本轮,不进行matric 记录
if skip_step:
self.timer.consume_durations()
time.sleep(1.0)
continue
# 记录 matrix
self.metric_logger.log(xxxx)
# 先停止源头数据
self.env.stop().wait()
self.rollout.stop().wait()
self.actor.stop().wait()
env_handle.wait()
rollout_handle.wait()
actor_handle.wait()
self._save_checkpoint()
这里值得注意的是:EnvWorker 被设计为 数据的“聚合与分发中心” ,汇总成轨迹(Trajectory)发送到 actor。
-
一个完整的训练轨迹(Trajectory)通常包含: 观察值 (Observations) 、 动作 (Actions) 、 奖励 (Rewards) 、 价值估计 (Values) 和 完成标记 (Dones) 。
因此,env worker 和 rollout worker 的轨迹数据分工如下:
- RolloutWorker 只负责推理,产出 Actions 和 Values 。
- EnvWorke 负责物理模拟交互,产出 Observations 和 Rewards 。
- 聚合逻辑 :为了减少跨进程通信的次数, EnvWorker 在执行 interact 的过程中,会实时接收来自 RolloutWorker 的推理结果,并将其与环境产生的奖励和观察值 就地打包 。
- 发送时机 :当一整段轨迹(Chunk)收集完成后, EnvWorker 调用 send_rollout_trajectories ,将这个“大礼包”一次性发送给 Actor 。
5. 总结
至此,单点控制层中大体逻辑就已经展开完成了。如图所示
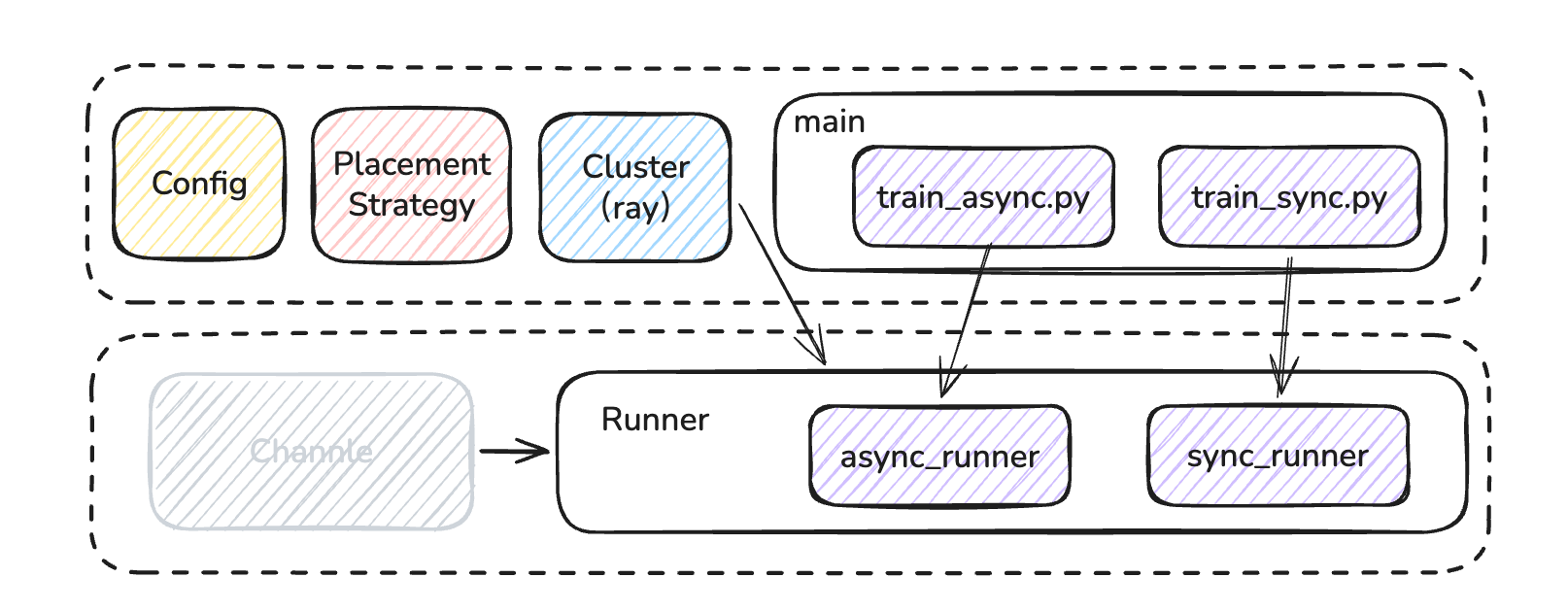
下一篇会从 Channle 开始说起,我们了解一下worker底层P2P通信是如何工作的。