- RLinf图解-Framework 与 Single Controller
- RLinf图解-Channel 与 Worker 通信
- RLinf图解-Dynamic Scheduler
- RLinf图解-Workflow 与 Data
Rlinf 中的 worker group和 runner 是组织算法的 workflow,通过 Runner 实现 MPMD的流程控制,通过 Worker Group实现 SPMD 的分布式控制,本章以具身 RL 训练为例子,详解一下 worker 之间的交互和具体的数据格式,为后续开发和改造提供理论基础
1. Runner主流程
在用户的代码中,主要做如下几个步骤:
- 初始化 Ray Cluster
- 设置组件放置策略
- 创建参与各种 role worker group
- 创建 runner,并启动 worker初始化和运行 MPMD主循环
runner 的 run 方法执行后,
def run(self):
start_step = self.global_step
start_time = time.time()
for _step in range(start_step, self.max_steps):
# set global step
self.actor.set_global_step(self.global_step)
self.rollout.set_global_step(self.global_step)
with self.timer("step"):
with self.timer("sync_weights"):
if _step % self.weight_sync_interval == 0:
self.update_rollout_weights()
with self.timer("generate_rollouts"):
env_handle: Handle = self.env.interact(
input_channel=self.env_channel,
rollout_channel=self.rollout_channel,
reward_channel=self.reward_channel,
actor_channel=self.actor_channel,
)
rollout_handle: Handle = self.rollout.generate(
input_channel=self.rollout_channel,
output_channel=self.env_channel,
)
if self.reward is not None:
reward_handle: Handle = self.reward.compute_rewards(
input_channel=self.reward_channel,
output_channel=self.env_channel,
)
self.actor.recv_rollout_trajectories(
input_channel=self.actor_channel
).wait()
rollout_handle.wait()
if self.reward is not None:
reward_handle.wait()
# compute advantages and returns.
with self.timer("cal_adv_and_returns"):
actor_rollout_metrics = (
self.actor.compute_advantages_and_returns().wait()
)
# actor training.
actor_training_handle: Handle = self.actor.run_training()
env_bootstrap_handle: Handle | None = None
if self.overlap_env_bootstrap and _step + 1 < self.max_steps:
env_bootstrap_handle = self.env.prefetch_train_bootstrap(
rollout_channel=self.rollout_channel
)
# Some metrics code
# .......
self.metric_logger.finish()
# Stop logging thread
self.stop_logging = True
self.log_queue.join() # Wait for all queued logs to be processed
self.log_thread.join(timeout=1.0)
大致就如以下时序图所示
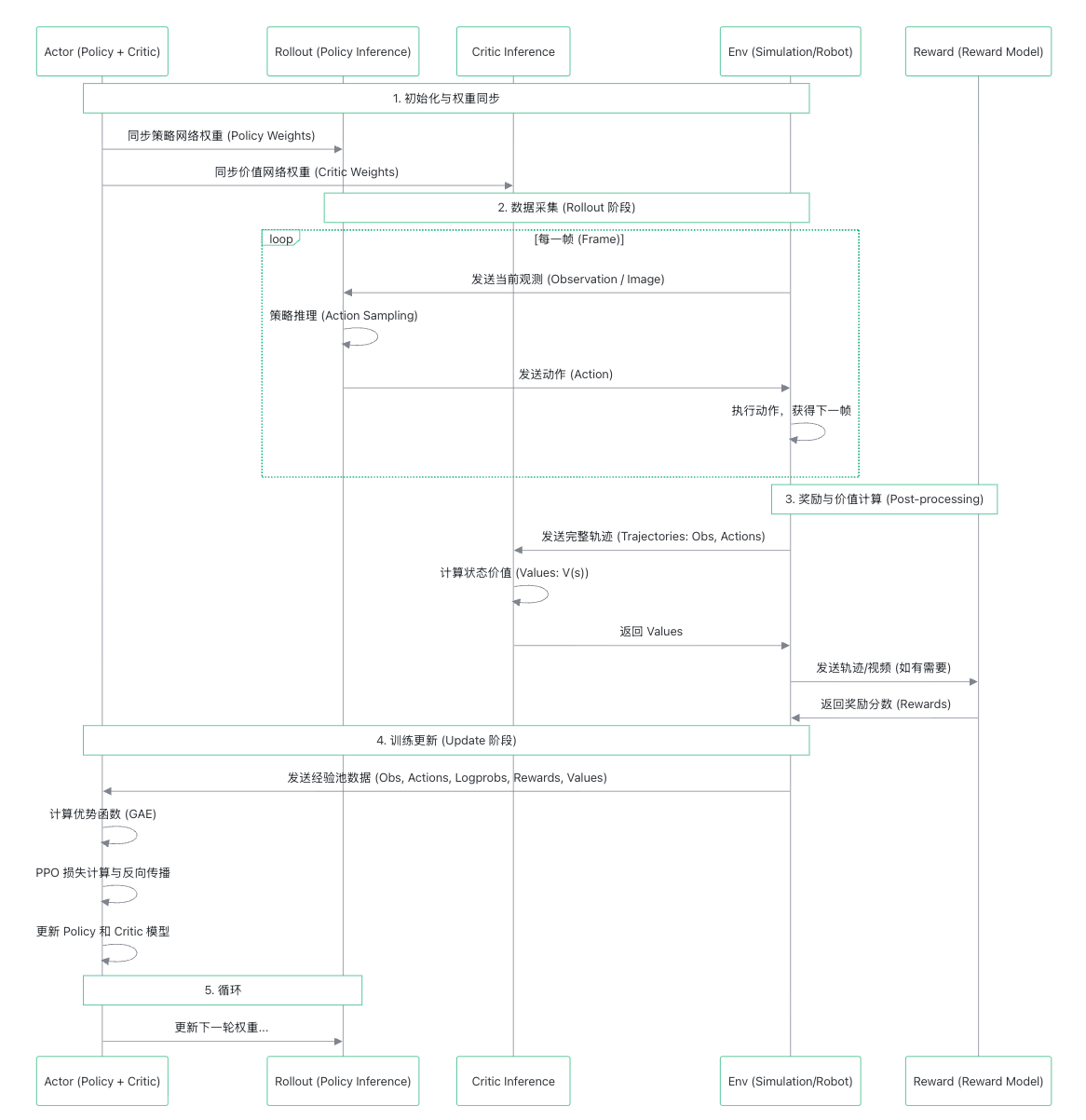
以上代码可以看出,在 Actor 同步权重后,进入 rollout 采集阶段,这里的采集第一步是 Env worker 给的输入。所以我们从 env worker group 开始讲起。
2. Role Worker配对与数据传输
既然不同的 role worker 都是group形式存在,那么不同的 group 的 worker 个数 就 可以按比例灵活配置。这就会涉及到不同rank 的 worker 之间配对映射关系,和他们之间传输、分发的数据如何分配问题。
rlinf 提供了一个准用的函数计算两个 group 之间通信的对应关系和 batch-size的如何切分发送。
class CommMapper:
# 计算目的 worker rank 的分配逻辑,用户数据发送
def get_dst_ranks(
batch_size: int, src_world_size: int, dst_world_size: int, src_rank: int
) -> list[tuple[int, int]]:
"""Compute destination ranks and transfer sizes for one source rank."""
# 要求数据的batch_size必须被 两组 worker平均分配
assert batch_size % src_world_size == 0, (
f"batch_size ({batch_size}) must be divisible by src_world_size ({src_world_size})."
)
assert batch_size % dst_world_size == 0, (
f"batch_size ({batch_size}) must be divisible by dst_world_size ({dst_world_size})."
)
assert 0 <= src_rank < src_world_size, (
f"src_rank ({src_rank}) must be in [0, {src_world_size})."
)
batch_size_per_src_rank = batch_size // src_world_size
batch_size_per_dst_rank = batch_size // dst_world_size
dst_ranks_and_sizes: list[tuple[int, int]] = []
# 根据src_rank的batch大小计算分割区间
batch_begin = src_rank * batch_size_per_src_rank
batch_end = (src_rank + 1) * batch_size_per_src_rank
while batch_begin < batch_end:
# 将数据切分至目标 des_rank 中,并截取数据大小,存入dst_ranks_and_sizes列表
dst_rank = batch_begin // batch_size_per_dst_rank
dst_batch_begin = dst_rank * batch_size_per_dst_rank
dst_remaining = batch_size_per_dst_rank - (batch_begin - dst_batch_begin)
src_remaining = batch_end - batch_begin
dst_size = min(dst_remaining, src_remaining)
dst_ranks_and_sizes.append((dst_rank, dst_size))
batch_begin += dst_size
return dst_ranks_and_sizes
# 计算源 worker rank 的分配逻辑,用于数据返回
def get_src_ranks(
batch_size: int, src_world_size: int, dst_world_size: int, dst_rank: int
) -> list[tuple[int, int]]:
"""Compute source ranks/sizes for one destination rank."""
assert batch_size % src_world_size == 0, (
f"batch_size ({batch_size}) must be divisible by src_world_size ({src_world_size})."
)
assert batch_size % dst_world_size == 0, (
f"batch_size ({batch_size}) must be divisible by dst_world_size ({dst_world_size})."
)
assert 0 <= dst_rank < dst_world_size, (
f"dst_rank ({dst_rank}) must be in [0, {dst_world_size})."
)
src_ranks_and_sizes: list[tuple[int, int]] = []
for src_rank in range(src_world_size):
dst_ranks_and_sizes = CommMapper.get_dst_ranks(
batch_size=batch_size,
src_world_size=src_world_size,
dst_world_size=dst_world_size,
src_rank=src_rank,
)
for mapped_dst_rank, size in dst_ranks_and_sizes:
if mapped_dst_rank == dst_rank:
src_ranks_and_sizes.append((src_rank, size))
expected_size = batch_size // dst_world_size
actual_size = sum(size for _, size in src_ranks_and_sizes)
assert actual_size == expected_size, (
f"Expected receive size {expected_size} for destination rank {dst_rank}, "
f"got {actual_size} from mappings {src_ranks_and_sizes}."
)
return src_ranks_and_sizes
3. Env Worker
3.1 env pipeline
仿真环境一般都运行时间较长,所以为了加快整体的训推速度,每次 env 和 sim 交互都是同时启动一批的仿真环境,并且为了加快与 rollout 的数据交互,会将仿真编排成多批次,组成 pipeline。
编排原则一般是不同的场景的仿真设置为一个 pipeline,其中 pipeline 中的个数是该仿真场景下需要并发多少个实例继续仿真模拟。
我们已下表的组合为例,举例说明:
| Actor Group | Rollout Group | Env Group | pipeline | sim parallet instance |
|---|---|---|---|---|
| 8 | 4 | 4 | 3 | 3 |
因此,交互的 worker 关系如下所示:
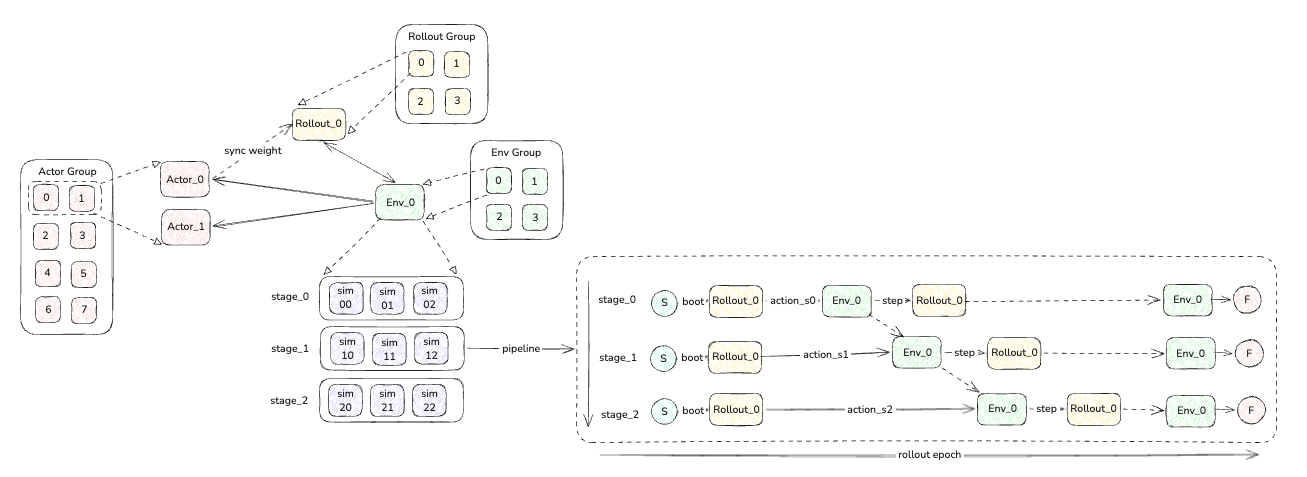
- 同步权重时,是每两个 actor worker 对应一个 rollout worker,这两个 actor worker 会选取0、2、4、6 等 rank 的 actor 把训练权重同步给 rollout worker 的0、1、2、3。
- Rollout worker 与 Env worker 是一一对应的。
- 每个 Env worker 的交互 pipeline (stage)为 3,每个pipeline 的 sim实例也为 3 个,因此每次一个 env worker 与 rollout worker 传输的 3 个实例的仿真obs 数据。通过右下的 pipeline 时序图可以大致观察一个 rollout epoch 的交互逻辑,这个 pipeline会执行n_train_chunk_steps次交互后结束
# n_train_chunk_steps定义如下,与 rollout 侧保持一致 self.n_train_chunk_steps = ( # 每次 epoch 的执行的总action迭代步数 cfg.env.train.max_steps_per_rollout_epoch # 每次推理,让仿真环境执行的 action 步数 // cfg.actor.model.num_action_chunks ) - 这里观察 pipeline 的最后一步,env worker会与仿真交互一次获取到 obs 发送到 rollout,对应 rollout 侧也有一个最后一步的推理,然后转换成ChunkStepResult缓存起来,这里多进行这一步主要是在计算GAE/return 时通常需要 T+1 个 value ( V(s_0..s_T) )来 bootstrap 最后一步,但前面的环境交互循环里只拿到了 T 个推理value输出,因此在epoch 结束时需要再拿一次“最后状态”的 value/bootstraps,把轨迹补齐这个 最有的 1 个 value。
for stage_id in range(self.stage_num): env_output = env_outputs[stage_id] # 这里是经验模型的输出,可以暂时忽略 if env_output.intervene_actions is not None: self.rollout_results[stage_id].update_last_actions( env_output.intervene_actions, env_output.intervene_flags, ) reward_model_output = None # 如果存在reward专属模型,这从模型中得到reward,最终会与 sim rewards 继续宁加权权平均 if reward_channel is not None: last_run = epoch == self.rollout_epoch - 1 reward_model_output = self.get_reward_model_output( env_output, send_channel=reward_channel, recv_channel=input_channel, last_run=last_run, ) if reward_model_output is not None: env_metrics["reward_model_output"].append( reward_model_output.detach().float().reshape(-1).cpu() ) rollout_result = self.recv_rollout_results(input_channel, mode="train") # 合并最终的 rewards rewards = self.compute_bootstrap_rewards( env_output, rollout_result.bootstrap_values, reward_model_output ) # 缓存结果 chunk_step_result = ChunkStepResult( prev_values=( rollout_result.prev_values if self.collect_prev_infos else None ), dones=env_output.dones, truncations=env_output.truncations, terminations=env_output.terminations, rewards=rewards, ) self.rollout_results[stage_id].append_step_result(chunk_step_result)
3.2 sim tensor data
Env worker 与仿真交互后,得到的是这一次 pipeline(stage)的所有仿真实例的结果。
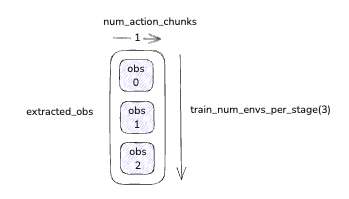
这个结果数据是一个整体的 tensor,其维度为[train_num_envs_per_stage, num_action_chunks].
- train_num_envs_per_stage就是并行的 sim instance 实例
- num_action_chunks就是每个sim实例执行的没一步action 后的 obs 的个数,以num_action_chunks=1为例,那么这个 tensor 的图形就如下所示
除了 obs 外,还有其他字段,我们从EnvOutput定义得知
@dataclass(kw_only=True)
class EnvOutput:
"""Environment output for a single chunk step."""
# 仿真实例,是一个[str, tensor]的 map
obs: dict[str, Any]
# 当仿真结束(正常、异常)时,所观察到的 obs
final_obs: Optional[dict[str, Any]] = None
# dones 代表仿真正常结束的状态矩阵:terminations OR truncations
# terminations 代表 自然终止 的状态矩阵:比如任务成功/失败、掉落、碰撞等环境定义的终止条件触发
# truncations 代表 截断终止 的状态矩阵:比如到达 time limit、外部强制中止、达到最大步数等“非任务本身终止”的原因
dones: Optional[torch.Tensor] = None # [B, T]
terminations: Optional[torch.Tensor] = None # [B, T]
truncations: Optional[torch.Tensor] = None # [B, T]
rewards: Optional[torch.Tensor] = None # [B, T]
我们以 dones 为例,如果B=3(3个 sim 实例),T=4(一次性执行 4 步 action),那么其矩阵如下:
# truncations: shape [B, T] = [3, 4]
truncations = torch.tensor([
[False, False, False, False], # env0 这 4 步都没截断
[False, True, False, False], # env1 在第 2 步发生过截断(中途)
[False, False, False, True ], # env2 在最后一步发生截断
], dtype=torch.bool)
# 然而,我们在env worker只取T最后一步的结果作为该step的状态,
# 因此env worker的step代码中会看到下面的写法
last_step_truncations = truncations[:, -1]
# 结果: tensor([False, False, True])
这 3 个矩阵主要是为了对后续的 gae 计算做部分值屏蔽处理:
- 在非 auto_reset 模式下计算loss_mask(下文会讲),从而在计算 gae 时屏蔽掉无效的 value 值
- 在auto_reset模式,当一个上一个仿真结束后,sim 环境会立即进行重置, 并将上一个sim 的 obs填充到final_obs,rollout 会对final_obs进行推理,产生bootstrap_values,而这个bootstrap_values,我们在计算 gae 时也要计算进去,那么如果加入到 gae 中呢?env worker 在 rewards 调整时,就会根据当前的 dones 或者truncations状态,将终止时刻的bootstrap_values加到 rewards 中
bootstrap_type = self.cfg.algorithm.get("bootstrap_type", "standard") if bootstrap_type == "standard": last_step_truncations = env_output.truncations[:, -1] else: last_step_truncations = env_output.dones[:, -1] if not last_step_truncations.any(): return adjusted_rewards final_values = torch.zeros_like(adjusted_rewards[:, -1], dtype=torch.float32) final_values[last_step_truncations] = ( bootstrap_values[last_step_truncations].reshape(-1).to(torch.float32) ) adjusted_rewards[:, -1] += self.cfg.algorithm.gamma * final_values return adjusted_rewards
这个 rewards 最后会传递给 actor worker 进行 gae 的计算,从而得出 advantage 和 retuns
4. Rollout Worker
rollout 整体逻辑比较简单,就是根据收到 env worker 的 obs 数据,进行推理,计算 valuse 值,然后返回给 env worker,不过由于 rollout worker 与 env worker 可能会存在 n:1 或 1:m 的情况,在接收 env 的数据是会进行 merge处理。
4.1 rollout envoutput merge
async def recv_env_output(
self, input_channel: Channel, mode: Literal["train", "eval"] = "train"
) -> dict[str, Any]:
"""Receive env outputs from mapped env ranks and merge if needed.
Args:
input_channel: Channel carrying env->rollout outputs.
mode: Rollout mode, either ``"train"`` or ``"eval"``.
Returns:
A single env output dict. When multiple env ranks are mapped to this
rollout worker, outputs are merged on batch dimension.
"""
assert mode in ["train", "eval"], f"{mode=} is not supported"
src_ranks_and_sizes = self.src_ranks[mode]
obs_batches = []
# 通过上文计算的对应关系,从目标 env worker 中获取数据
for src_rank, expected_size in src_ranks_and_sizes:
obs_batch = await input_channel.get(
key=CommMapper.build_channel_key(
src_rank, self._rank, extra=f"{mode}_obs"
),
async_op=True,
).async_wait()
actual_size = self._infer_env_batch_size(obs_batch)
assert actual_size == expected_size, (
f"Expected env output batch size {expected_size} from env rank {src_rank}, "
f"got {actual_size}."
)
obs_batches.append(obs_batch)
# 然后将获取的目标数据数据中的 tensor 进行merge,组成一个大的结构体,方便一次性推理
# {"obs": merged_obs, "final_obs": merged_final_obs}
return self._merge_obs_batches(obs_batches)
4.2 rollout send actions
相反,在推理结束后,我们还需要将推理的数据进行拆分,把属于不同的env worker 的数据发送到对应的 rank
def send_chunk_actions(
self,
output_channel: Channel,
chunk_actions: torch.Tensor | np.ndarray,
mode: Literal["train", "eval"] = "train",
):
"""Send action shards to mapped env ranks.
Args:
output_channel: Channel carrying rollout->env action chunks.
chunk_actions: Predicted action chunk batch (tensor or ndarray).
mode: Rollout mode, either ``"train"`` or ``"eval"``.
"""
assert mode in ["train", "eval"], f"{mode=} is not supported"
dst_ranks_and_sizes = self.dst_ranks[mode]
# 从 dst_ranks中获取,每个 env worker 需要发送多大 batch size 是数据,并进行分割发送
split_sizes = [size for _, size in dst_ranks_and_sizes]
chunk_actions_split = self._split_actions(chunk_actions, split_sizes)
for (dst_rank, _), chunk_action_i in zip(
dst_ranks_and_sizes, chunk_actions_split
):
if isinstance(chunk_action_i, torch.Tensor):
chunk_action_i = (
chunk_action_i.detach().cpu().contiguous()
) # for evaluation
output_channel.put(
chunk_action_i,
key=CommMapper.build_channel_key(
self._rank, dst_rank, extra=f"{mode}_actions"
),
async_op=True,
)
5.Actor Wroker
5.1 actor recv trajectory
action在接收轨迹时,跟 rollout 与 env 交互时类似,需要拆解数据,不同的 actor rank 需要计算从哪些 env worker 中获取数据,我们看一下代码逻辑
sync def recv_rollout_trajectories(self, input_channel: Channel) -> None:
"""
Receive rollout trajectories from rollout workers.
Args:
input_channel: The input channel to read from.
"""
clear_memory(sync=False)
# 计算这个 actor rank worker 的 input_channel 有多少批数据存在
send_num = self._component_placement.get_world_size("env") * self.stage_num
recv_num = self._component_placement.get_world_size("actor")
split_num = compute_split_num(send_num, recv_num)
recv_list = []
# 每批数据取一次
for _ in range(split_num):
trajectory: Trajectory = await input_channel.get(async_op=True).async_wait()
recv_list.append(trajectory)
# 把trajectories list 合并成一个大的 dictionary,其 value 为合并的 tensor
self.rollout_batch = convert_trajectories_to_batch(recv_list)
# 如果是 not auto_reset模式,这里需要对 reward 进行过滤,并改变 reward 的 shape,
# 方便后面的 adv 的计算,同时也生成loss_mask矩阵,在 adv 计算屏蔽需要忽略的 values
self.rollout_batch = self._process_received_rollout_batch(self.rollout_batch)
5.2 adv and return (gae)
advantage 计算是通过注册机制实现的,通过配置文件中指定的算法会调用不同的计算函数,我们以 gae 算法为例说明。
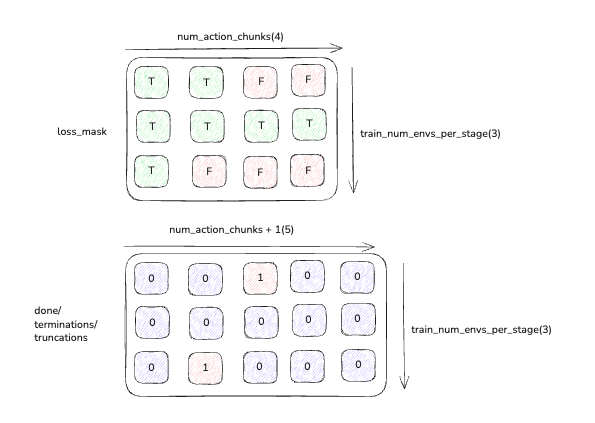
其中dones和loss_mask直接的关系如下图所示:
def compute_advantages_and_returns(self) -> dict[str, torch.Tensor]:
"""
Compute the advantages and returns.
"""
# 这里转换为标准的输入参数
kwargs = {
"task_type": self.cfg.runner.task_type,
"adv_type": self.cfg.algorithm.adv_type,
"rewards": self.rollout_batch["rewards"],
"dones": self.rollout_batch["dones"],
"values": self.rollout_batch.get("prev_values", None),
"gamma": self.cfg.algorithm.get("gamma", 1),
"gae_lambda": self.cfg.algorithm.get("gae_lambda", 1),
"group_size": self.cfg.algorithm.get("group_size", 8),
"reward_type": self.cfg.algorithm.reward_type,
"loss_mask": self.rollout_batch.get("loss_mask", None),
"loss_mask_sum": self.rollout_batch.get("loss_mask_sum", None),
}
# adv的核心计算函数
advantages_and_returns = calculate_adv_and_returns(**kwargs)
# 统计rollout的metrics数据
self.rollout_batch.update(advantages_and_returns)
if kwargs["loss_mask"] is not None:
self.rollout_batch.update({"loss_mask": kwargs["loss_mask"]})
if kwargs["loss_mask_sum"] is not None:
self.rollout_batch.update({"loss_mask_sum": kwargs["loss_mask_sum"]})
# 获得rewards的统计信息,并打印
rollout_metrics = compute_rollout_metrics(self.rollout_batch)
return rollout_metrics
def calculate_adv_and_returns(**kwargs) -> tuple[torch.Tensor, Optional[torch.Tensor]]:
"""
Unified entry for advantage + return computation.
Accepts variable keyword arguments, preprocesses them, then dispatches
to specific algorithm via registry.
"""
adv_type = kwargs["adv_type"]
# 查找gae的计算方法
fn = get_adv_and_returns(adv_type)
task_type = kwargs["task_type"]
# 我们主要看embodied类型的计算,LLM的计算和 VLA 差别较大,暂时忽略
if task_type == "embodied":
# 1. 如果计算 rewards 是通过chunk_level方式,即我们不需要统计每一步的action的结果
# 那么我们需要把rewards、dones、loss_mask、loss_mask_sum等值压缩成一维
# 2. 获取最新的 reward 的shape[num_chunk,batch_size, chunk_size]
# n_steps = num_chunk * chunk_size
kwargs = preprocess_embodied_advantages_inputs(**kwargs)
# 除了 gae(PPO) 外,还有其他算法: grpo、grpo_dynamic、reinpp、raw
if adv_type != "gae":
kwargs = calculate_scores(**kwargs)
advantages, returns = fn(**kwargs)
# 将结果展开维一维数据,进行 batch training
res = postprocess_embodied_advantages_outputs(
advantages=advantages, returns=returns, **kwargs
)
else:
# reasoning tasks
kwargs = preprocess_reasoning_advantages_inputs(**kwargs)
advantages, returns = fn(**kwargs)
res = postprocess_reasoning_advantages_outputs(advantages, returns)
return res
我们看一下 gae 的具体实现
@register_advantage("gae")
def compute_gae_advantages_and_returns(
rewards: torch.Tensor,
gamma: float = 1.0,
gae_lambda: float = 1.0,
values: Optional[torch.Tensor] = None,
normalize_advantages: bool = True,
normalize_returns: bool = False,
loss_mask: Optional[torch.Tensor] = None,
dones: Optional[torch.Tensor] = None,
**kwargs,
) -> tuple[torch.Tensor, torch.Tensor]:
"""
Calculate advantages and returns for Proximal Policy Optimization (PPO).
NOTE: currently this function does not support auto-reset.
This function implements Generalized Advantage Estimation (GAE) to compute
advantages and returns for PPO training. The advantages are normalized
using mean and standard deviation for stable training.
Args:
rewards (torch.Tensor): Rewards per timestep. Shape: [seq_len, bsz].
values (torch.Tensor): Value function estimates. Shape: [seq_len, bsz].
dones (torch.Tensor): Done flags (1 if episode ended, else 0).
gamma (float, optional): Discount factor. Defaults to 1.0.
gae_lambda (float, optional): GAE smoothing factor. Defaults to 1.0.
normalize_advantages (bool, optional): Whether to normalize advantages. Defaults to True.
normalize_returns (bool, optional): Whether to normalize returns. Defaults to False.
Returns:
Tuple[torch.Tensor, torch.Tensor]: (advantages, returns)
"""
T = rewards.shape[0]
advantages = torch.zeros_like(rewards)
returns = torch.zeros_like(rewards)
gae = 0
# 如果没有value,则不是 critic 计算方式,不需要加权平均
critic_free = values is None
if critic_free:
gae_lambda = 1
gamma = 1
# 从后向前进行训练计算,rewards为T维,values和dones为T+1维
for step in reversed(range(T)):
if critic_free:
delta = rewards[step]
else:
delta = (
rewards[step]
+ gamma * values[step + 1] * (~dones[step + 1])
- values[step]
)
gae = delta + gamma * gae_lambda * (~dones[step + 1]) * gae
returns[step] = gae if critic_free else gae + values[step]
advantages = returns - values[:-1] if not critic_free else returns
# 对 loss_mask没有屏蔽的 adv 做归一化,为了让训练的只标准化,稳定训练,
if normalize_advantages:
advantages = safe_normalize(advantages, loss_mask=loss_mask)
# 同样return也可以做归一化
if normalize_returns:
returns = safe_normalize(returns, loss_mask=loss_mask)
return advantages, returns
5.3 training
在获得了 adv 和 returns 后,我们就可以开始训练,我们看一下 actor 训练的主函数run_training
def run_training(self) -> None:
"""
Run the training process using the received rollout batch.
"""
# 权重加载回 GPU
if self.is_weight_offloaded:
self.load_param_and_grad(self.device)
if self.is_optimizer_offloaded:
self.load_optimizer(self.device)
# 切换训练模式
self.model.train()
rollout_size = (
self.rollout_batch["prev_logprobs"].shape[0]
* self.rollout_batch["prev_logprobs"].shape[1]
)
# 生成logprobs的维度矩阵,并对self.rollout_batch进行随机 shuffle,提升训练稳定性
g = torch.Generator()
g.manual_seed(self.cfg.actor.seed + self._rank)
# 生成 [0, rollout_size) 的随机排列
shuffle_id = torch.randperm(rollout_size, generator=g)
with torch.no_grad():
self.rollout_batch = process_nested_dict_for_train(
self.rollout_batch, # rollout batch(常见为 [T, B, ...])
shuffle_id # 展平后的随机索引
)
# 检查全局 batch 是否能被 micro_batch 与 world_size 整除
# 需要整除才能保证梯度累积步数为整数
assert (
self.cfg.actor.global_batch_size # 全局 batch size(跨所有 DP rank)
% (self.cfg.actor.micro_batch_size * self._world_size) # 每次累积的总微批容量
== 0
), "global_batch_size is not divisible by micro_batch_size * world_size"
# 计算梯度累积步数(每个 rank)
self.gradient_accumulation = (
self.cfg.actor.global_batch_size
// self.cfg.actor.micro_batch_size
// self._world_size
)
# 将展平数据切分成可迭代的 mini-batch
# PPO 通常对同一批数据做多轮更新. https://arxiv.org/abs/1707.06347
rollout_size = self.rollout_batch["prev_logprobs"].size(0)
batch_size_per_rank = self.cfg.actor.global_batch_size // self._world_size
assert rollout_size % batch_size_per_rank == 0, (
f"{rollout_size} is not divisible by {batch_size_per_rank}"
)
metrics = {}
update_epoch = self.cfg.algorithm.get("update_epoch", 1)
for _ in range(update_epoch):
# 把展平后的数据切成若干个 per-rank global batch
rollout_dataloader_iter = split_dict_to_chunk(
self.rollout_batch,
rollout_size // batch_size_per_rank,
)
for train_global_batch in rollout_dataloader_iter:
# 将 global batch 再切成 micro batch 做梯度累积
train_global_batch_size = train_global_batch["prev_logprobs"].shape[0]
# 校验 global batch 的大小与配置匹配
assert (
train_global_batch_size
== self.cfg.actor.global_batch_size
// torch.distributed.get_world_size()
)
# 校验 micro batch 可整除
assert train_global_batch_size % self.cfg.actor.micro_batch_size == 0, (
f"{train_global_batch_size=}, {self.cfg.actor.micro_batch_size}"
)
# 将该 global batch 切成 micro batch
train_micro_batch = split_dict_to_chunk(
train_global_batch,
train_global_batch_size // self.cfg.actor.micro_batch_size,
)
# 清空优化器梯度,为本 global batch 的累积做准备
self.optimizer.zero_grad()
# 遍历每个 micro batch
for idx, batch in enumerate(train_micro_batch):
# 将该 micro batch 的所有 tensor 移动到本地 GPU
batch = put_tensor_device(
batch,
f"{Worker.torch_device_type}:{int(os.environ['LOCAL_RANK'])}",
)
# 设置 FSDP/no_sync 等上下文(最后一次 micro batch 才同步)
backward_ctx = self.before_micro_batch(
self.model,
is_last_micro_batch=(idx + 1) == self.gradient_accumulation,
)
advantages = batch["advantages"]
prev_logprobs = batch["prev_logprobs"]
returns = batch.get("returns", None)
prev_values = batch.get("prev_values", None)
loss_mask = batch.get("loss_mask", None)
loss_mask_sum = batch.get("loss_mask_sum", None)
forward_inputs = batch.get("forward_inputs", None)
# 针对不同 model_type 的额外前向参数
kwargs = {}
if SupportedModel(self.cfg.actor.model.model_type) in [
SupportedModel.OPENVLA,
SupportedModel.OPENVLA_OFT,
]:
kwargs["temperature"] = (
self.cfg.algorithm.sampling_params.temperature_train
)
kwargs["top_k"] = self.cfg.algorithm.sampling_params.top_k
elif (
SupportedModel(self.cfg.actor.model.model_type)
== SupportedModel.GR00T
):
kwargs["prev_logprobs"] = prev_logprobs
# 是否需要在 actor 前向中计算 values
compute_values = (
True if self.cfg.algorithm.adv_type == "gae" else False
)
# 自动混合精度上下文(降低显存/加速)
with self.amp_context:
output_dict = self.model(
forward_inputs=forward_inputs, # rollout的直接输入
compute_logprobs=True, # 需要当前策略 logprob(PPO loss)
compute_entropy=self.cfg.algorithm.entropy_bonus > 0, # 是否启用熵奖励则计算 entropy
compute_values=compute_values,
use_cache=False, # 训练禁用 cache,避免显存增长
**kwargs,
)
# GR00T会在前向中重算/更新 prev_logprobs
if (
SupportedModel(self.cfg.actor.model.model_type)
== SupportedModel.GR00T
):
prev_logprobs = output_dict["prev_logprobs"]
kwargs = { # 构造统一 loss 入口所需参数字典
"loss_type": self.cfg.algorithm.loss_type, # 策略/价值损失类型
"logprob_type": self.cfg.algorithm.logprob_type, # logprob 的组织方式(action/token)
"reward_type": self.cfg.algorithm.reward_type, # reward 的组织方式(action/chunk)
"single_action_dim": self.cfg.actor.model.get("action_dim", 7), # 单步 action 维度
"logprobs": output_dict["logprobs"], # 当前策略 logprobs
"values": output_dict.get("values", None), # 当前 value 预测(可能为 None)
"old_logprobs": prev_logprobs, # 旧策略 logprobs(重要性采样)
"advantages": advantages, # 优势
"returns": returns, # 回报(用于 value loss)
"prev_values": prev_values, # 旧 values(用于 value clipping)
"clip_ratio_high": self.cfg.algorithm.clip_ratio_high, # PPO clip 上界
"clip_ratio_low": self.cfg.algorithm.clip_ratio_low, # PPO clip 下界
"value_clip": self.cfg.algorithm.get("value_clip", None), # value clip 系数(可选)
"huber_delta": self.cfg.algorithm.get("huber_delta", None), # huber loss delta(可选)
"loss_mask": loss_mask, # 有效位置 mask(屏蔽无效步)
"loss_mask_sum": loss_mask_sum, # mask 长度/计数(用于统计/缩放)
"max_episode_steps": self.cfg.env.train.max_episode_steps, # 环境最大步数(用于某些指标/缩放)
"task_type": self.cfg.runner.task_type, # task 类型(embodied/reasoning)
"critic_warmup": ( # critic warmup 期间可能只训练 value 或跳过某些项
self.optimizer_steps < self.critic_warmup_steps # 是否仍处于 warmup 步数内
), # 得到布尔值
} # loss 计算参数字典构造完成
# 计算损失并返回一组指标
loss, metrics_data = policy_loss(**kwargs)
# 初始化熵项(默认 0)
entropy_loss = torch.tensor(
0.0, device=Worker.torch_platform.current_device()
)
# 若启用熵奖励且不在 critic warmup 期
if (
self.cfg.algorithm.entropy_bonus > 0
and not kwargs["critic_warmup"]
):
# 满足则计算熵项
entropy = output_dict["entropy"] # 从模型输出取 entropy
entropy = reshape_entropy( # 根据 entropy_type/action_dim 重新整理形状
entropy, # 输入 entropy
entropy_type=self.cfg.algorithm.entropy_type, # 熵的组织方式
action_dim=self.cfg.actor.model.get("action_dim", 7), # action 维度
batch_size=output_dict["logprobs"].shape[0], # batch 大小
) # 输出 reshape 后 entropy
entropy_loss = masked_mean(entropy, mask=loss_mask) # 在有效位置上求熵均值
loss -= self.cfg.algorithm.entropy_bonus * entropy_loss # 将熵奖励加入总 loss(减去负熵)
metrics_data["actor/entropy_loss"] = entropy_loss.detach().item() # 记录熵项指标
# 若启用 SFT 协同训练
if self.enable_sft_co_train:
# 在同一次迭代里加入 SFT loss/指标
self._train_sft_epoch(metrics_data, loss)
# 按累积步数缩放 loss,保证等效于大 batch
loss /= self.gradient_accumulation
# 在 FSDP/no_sync 上下文里做反向传播
with backward_ctx:
self.grad_scaler.scale(loss).backward()
# 记录缩放后的 total_loss
metrics_data["actor/total_loss"] = loss.detach().item()
# 将本 micro batch 的指标追加到 metrics 容器
append_to_dict(metrics, metrics_data)
# micro batch 结束后清理缓存,降低峰值显存
self.torch_platform.empty_cache()
# 执行一次优化器 step,并返回梯度范数与学习率
grad_norm, lr_list = self.optimizer_step()
# 构造优化相关指标
data = {
"actor/grad_norm": grad_norm,
"actor/lr": lr_list[0],
}
if len(lr_list) > 1:
# 记录 critic 学习率
data["critic/lr"] = lr_list[1]
append_to_dict(metrics, data)
# 更新学习率调度器
self.lr_scheduler.step()
# 再次清空梯度,避免残留
self.optimizer.zero_grad()
# 释放临时张量/缓存(自定义工具)
clear_memory()
# 对指标列表取均值
mean_metric_dict = {key: np.mean(value) for key, value in metrics.items()}
# 跨分布式 rank 聚合指标(取平均)
mean_metric_dict = all_reduce_dict(
mean_metric_dict, op=torch.distributed.ReduceOp.AVG
)
# 返回本次训练迭代的全局平均指标
return mean_metric_dict
至此,一轮 epoch 的训练就完毕, 接下来会进入下一个循环,同步权重给 rollout,重新进行 env 和 rollout 的交互。
6. 总结
本章通过串联 Env、Rollout、Actor 等 worker 的一些关键函数,将 worker 直接交互流程、数据流拆分等细节进行了讲解,补全了第一节中的时序流程图。在 rlinf 框架中这段 RL 逻辑还只是冰山一角,在支持 LLM、Agentic 等方向的 RL 计算中,还会有不同的算法、流程、数据处理的变化,这些在以后的分析中逐步再继续展开。