- RLinf图解-Framework 与 Single Controller
- RLinf图解-Channel 与 Worker 通信
- RLinf图解-Dynamic Scheduler
- RLinf图解-Workflow 与 Data
在真实大规模训练时,我们往往要使用 DP+PP+TP 等并行化技术,可以通过这篇文章详细了解,从而实现超大参数模型的分布式的高利用率训练。 那么在 RLinf 内部的动态调度,如让 GPU 可以更高效的被使用?本文将探究这个问题。
1. Dynamic scheduler 的使用
在 RLinf 的 example«examples/reasoning/main_grpo.py» 中,在训练 LLM 时使用了 dynamic scheduler,代码如下
if component_placement._placement_mode == PlacementMode.AUTO:
scheduler_placement_strategy = NodePlacementStrategy(node_ranks=[0])
scheduler = SchedulerWorker.create_group(cfg, component_placement).launch(
cluster=cluster,
name="DynamicScheduler",
placement_strategy=scheduler_placement_strategy,
)
else:
scheduler = None
runner = ReasoningRunner(
cfg=cfg,
placement=component_placement,
train_dataset=train_ds,
val_dataset=val_ds,
rollout=rollout_group,
actor_inference=actor_inference_group,
actor=actor_group,
reward=reward_group,
scheduler=scheduler,
# critic components are only used for PPO
critic_inference=critic_inference_group,
critic=critic_group,
)
实质上是创建了一个单 scheduler worker,放置在 node 上,所以整体架构如下图所示:
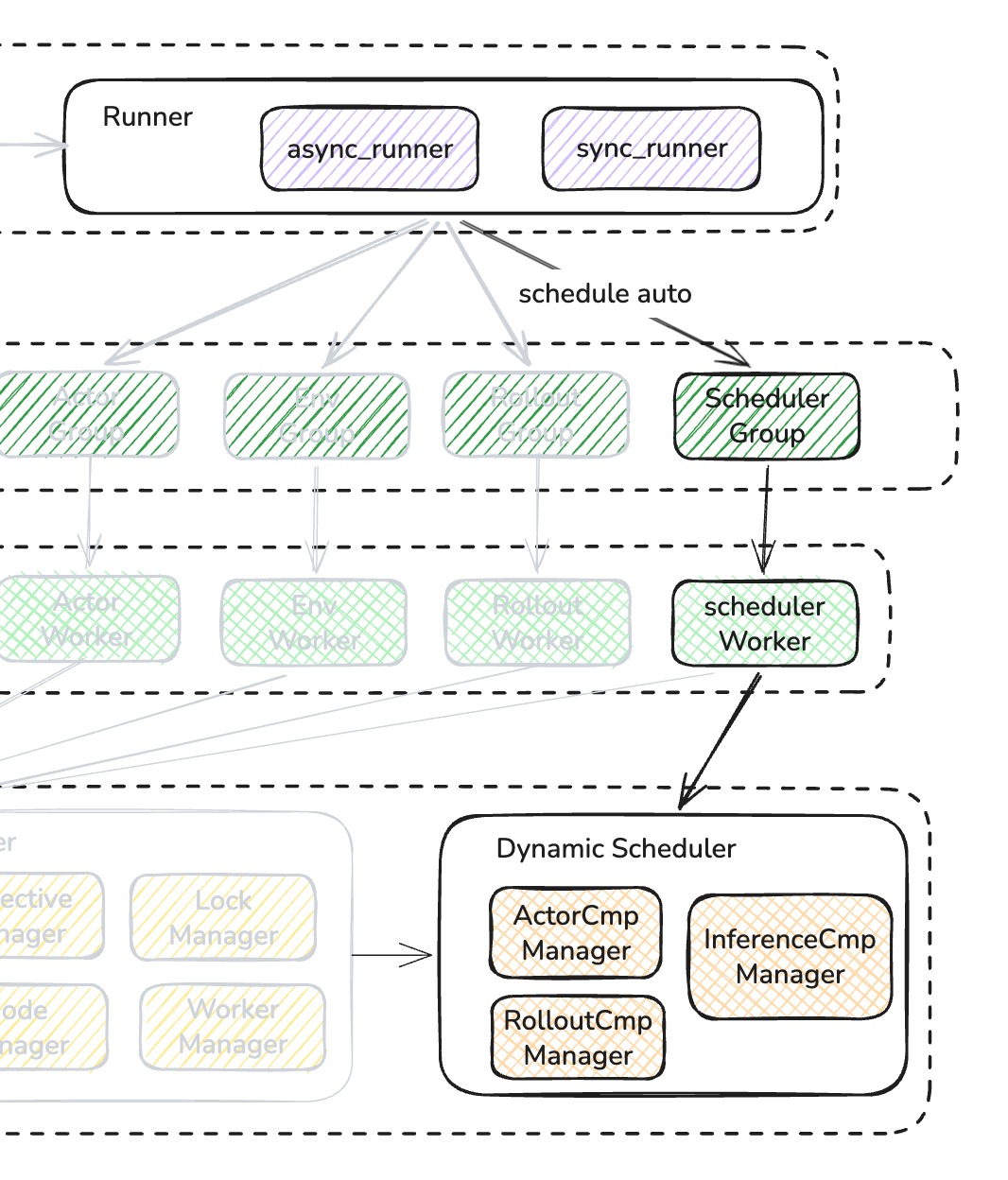
我们先看一下 runner 内部是如何使用 scheduler 的
class ReasoningRunner:
def __init__self,
cfg: DictConfig,
placement: "ModelParallelComponentPlacement",
train_dataset: Dataset,
val_dataset: Optional[Dataset],
rollout: Union["SGLangWorker", "VLLMWorker"],
actor_inference: Optional[Union["MegatronActorInference", "FSDPInference"]],
actor: Union["FSDPActor", "MegatronActor"],
reward: Optional["RewardWorker"],
scheduler: "SchedulerWorker" = None,
# critic components are only used for PPO
critic_inference: Optional[
Union["MegatronCriticInference", "FSDPInference"]
] = None,
critic: Optional["MegatronCritic"] = None,
):
# .... some codes
self.scheduler = scheduler
# .... some codes
def run(self):
epoch_iter = range(self.epoch, self.cfg.runner.max_epochs)
if len(epoch_iter) <= 0:
# epoch done
return
global_pbar = tqdm(
initial=self.global_steps,
total=self.max_steps,
desc="Global Step",
ncols=1280,
)
self.run_timer.start_time()
for _ in epoch_iter:
for batch in self.train_dataloader:
with self.timer("step"):
with self.timer("prepare_data"):
self._put_batch(batch)
with self.timer("sync_weights"):
self._sync_weights()
# 这里可以看到直接调用schedule方法,进行调度
if self.scheduler is not None:
scheduler_handle = self.scheduler.schedule()
# .... some codes
# Critic training
if self.critic:
critic_train_handle: Handle = self.critic.run_training(
input_channel=critic_training_input_channel,
output_channel=critic_training_output_channel,
compute_rollout_metrics=False,
)
else:
critic_train_handle = None
# actor training
if not critic_warmup:
actor_handle: Handle = self.actor.run_training(
input_channel=actor_training_input_channel, do_offload=False
)
else:
actor_handle = None
actor_metrics = None
if actor_handle:
actor_metrics = actor_handle.wait()
critic_training_metrics = None
if critic_train_handle is not None:
critic_metrics = critic_train_handle.wait()
_, critic_training_metrics = critic_metrics[0]
# 等待本轮调度完成
if self.scheduler is not None:
scheduler_handle.wait()
# .... some codes
L47:从代码可以看出,调度器在loop 的开始阶段进行一轮调度安排,进行 RL 训练,最后等待当前调度到达调度停止阈值后,L79 行放行,进入下一轮调度。
接下来我们重点看一下SchedulerWorker的具体实现
2. Scheduler Worker
我们先看worker 定义和初始部分
class SchedulerWorker(Worker):
"""Dynamic Scheduler."""
def __init__(
self,
config: DictConfig,
component_placement: ComponentPlacement,
workflow: list[str] = ["rollout", "inference", "actor"],
):
"""Initialize the SchedulerWorker."""
super().__init__()
self.cfg = config
self.component_placement = component_placement
self.components = self.component_placement.components
self.workflow = workflow
# 推理端目前支持 sglang 和 vllm 推理框架
assert self.cfg.rollout.rollout_backend in ["sglang", "vllm"], (
"only sglang and vllm are supported for dynamic scheduler"
)
# 训练端只支持 megatron
assert self.cfg.actor.training_backend == "megatron", (
"only megatron is supported for dynamic scheduler"
)
# 必须存在rollout和actor组件的放置方案
assert "rollout" in self.components, "rollout component is required"
assert "actor" in self.components, "actor component is required"
# Rollout(推理)在每个 step 开始时需要占用 actor 的 GPU 资源来进行数据生成。
# 但如果 rollout 还没生成完数据就释放资源给 actor,会导致数据pipeline断流。
# 因此开启这个策略,保证:
# - Rollout 持续占用 actor 的 GPU 资源。
# - 轮询检查 running_tasks (当前正在运行的任务数)是否降到阈值(默认为 rollout_total_tasks // 2 )以下。
# - 只有当 rollout 的任务积压降到阈值以下时,才执行 migrate 将 actor 的 GPU 资源释放出来给训练用。
# - 这确保了 rollout 有足够的任务积压来保持 pipeline 饱和,同时也不会无限期占用。
self.use_pre_process_policy = getattr(
self.cfg.cluster, "use_pre_process_policy", True
)
# 在最后一个迭代开始前,如果还有 rollout 任务在运行,直接开始 actor 更新会导致数据不一致或丢失。
# 因此开启这个策略,保证:
# - 在倒数第二次迭代时,检查 use_wait_before_last_iter_policy 开关。
# - 如果开启,执行 RolloutAction.Wait_For_Finish ,等待所有正在运行的 rollout 任务完成后再继续。
# - 这确保了在进入最终训练阶段前,所有推理任务都已收尾。
self.use_wait_before_last_iter_policy = getattr(
self.cfg.cluster, "use_wait_before_last_iter_policy", True
)
# Create ComponentManager
component_manager_kwargs = {
"config": config,
"component_placement": component_placement,
"use_pre_process_policy": self.use_pre_process_policy,
"use_wait_before_last_iter_policy": self.use_wait_before_last_iter_policy,
"_logger": self._logger,
"channel_factory": self.create_channel,
}
self.component_managers: dict[str, ComponentManager] = {}
for component in self.components:
# reword 组件使用 CPU,不需要做调度
if component == "reward":
continue
# 为rollout、actor、inference组件创建ComponentManager
self.component_managers[component] = create_component_manager(
component, component_manager_kwargs
)
# 创建全局 DynamicSchedulerState,存储当前的 GPU 资源分配情况
set_global_scheduer_state(
self.cfg,
self.component_placement._cluster_num_gpus,
self.component_managers,
)
# 本地做一个副本,后续操作都在本地进行
self.scheduler_state = get_global_scheduer_state()
async def schedule(self):
"""Run the scheduler."""
await self.pre_process()
await self.main_loop()
async def pre_process(self):
# rollout 先预热, 因此一切的动作源头是 rollout 开始,确保先预热,启动一些任务
await self.component_managers["rollout"].pre_process()
# 其他组件(inference, actor)预热
for component, manager in self.component_managers.items():
if component != "rollout":
await manager.pre_process()
# 重置本轮调度状态(可用 gpu 数清零、 组件实例数恢复默认配置个数)
'''
def reset(self):
"""Reset state."""
self.available_gpu_num = 0
for component, manager in self.component_managers.items():
self.components_instance_num[component] = manager.current_instance_num
'''
self.scheduler_state.reset()
async def main_loop(self):
"""Main loop. Trying to release or allocate gpu resource for each components by workflow after actor ready to update."""
for train_iter in range(self.cfg.algorithm.n_minibatches):
# actor component manager 会等待上一次的训练都已经执行完毕
await self.component_managers["actor"].wait_for_actor_update()
# Trying to release or allocate resource for each components by workflow
resource_info = f"[Release && Allocate Info] After train-iter{train_iter}n"
for component in self.workflow:
# rollout->inference->actor
if component not in self.component_managers:
self.log_warning(f"can't find ComponentManager for {component}")
continue
# 1. release instance numbers
# 2. allocate instance numbers
released_gpu_num, incremental_gpu_num = await self.component_managers[
component
].release_or_allocate(train_iter)
self.scheduler_state.update(
component, released_gpu_num, incremental_gpu_num
)
resource_info += (
f"{component} : released_gpu_num = {released_gpu_num}, "
f"incremental_gpu_num={incremental_gpu_num} => "
f"available_gpu_num={self.scheduler_state.available_gpu_num}n"
)
self.log_info(resource_info)
L74:可以看到调度方法,会做两步动作,pre_process 和 main_loop
- pre_process:在每个全局 step 开始前,重置各组件状态并执行资源预分配策略。
- Rollout 先执行 pre_process :因为 rollout 需要先占用 actor 的 GPU 资源来开始数据生成
- 其他组件(Inference, Actor)执行 pre_process :初始化各自的状态
- 重置 scheduler_state :清空全局调度状态,准备新一轮调度
- main_loop: 在每个训练迭代中,按 workflow 顺序协调各组件的 GPU 资源分配/释放。
- 遍历每个训练小批次 ( n_minibatches )
- 等待 Actor 更新完成 :确保上一次训练已经完成
- 按 workflow 顺序调度资源 : rollout → inference → actor
- 调用 release_or_allocate(train_iter) 让各 ComponentManager 决定是释放还是分配 GPU
- 更新全局调度状态 scheduler_state
L112: 可以看出,调度的关键步骤是 release_or_allocate 方法,然后返回释放 和 分配了多少 GPU 资源。
L116: 将现在释放和分配的 gpu 信息输入到全局状态管理后,得出available_gpu_num。
接下来,我看一下各个 component manager 具体是如何分配和释放 GPU 资源的
3. Component Manager
我们先看一下 manager 的基类ComponentManager
class ComponentManager(ABC):
def __init__(
self,
component_role: str,
config: DictConfig,
component_placement: ModelParallelComponentPlacement,
use_pre_process_policy: bool,
use_wait_before_last_iter_policy: bool,
channel_factory: Callable[[str], Channel],
_logger: Logger,
):
self.component_role = component_role
self.cfg = config
self.component_placement = component_placement
self.use_pre_process_policy = use_pre_process_policy
self.use_wait_before_last_iter_policy = use_wait_before_last_iter_policy
self.channel_factory = channel_factory
self._logger = _logger
self.n_minibatches = self.cfg.algorithm.n_minibatches
assert self.component_role in self.component_placement._components
# 以下代码相对重要
self.init_instance_num = getattr(
component_placement, f"{self.component_role}_dp_size"
)
self.init_gpu_num = getattr(
component_placement, f"{self.component_role}_world_size"
)
# 此处 model_parallel_size 表示每个实例占用的 GPU 数量
# 后续,我们调度是以实例为颗粒度的,所有分配、释放GPU nums = instance_nums * model_parallel_size
self.model_parallel_size = self.init_gpu_num // self.init_instance_num
self.reset()
def _create_channel(
self,
channel_name: str,
maxsize: int = 0,
distributed: bool = False,
node_rank: int = 0,
local: bool = False,
):
from ..channel.channel import Channel
return Channel.create(
name=channel_name,
maxsize=maxsize,
distributed=distributed,
node_rank=node_rank,
local=local,
)
def create_channels(self, channel_num: int):
"""Create channels and queues for communication, and each channel is for a single instance.
Args:
channel_num (int): The number of channel.
"""
self.channels: list[Channel] = []
# 当创建一组channel时,我们需要初始双向 queue,下面是两个 queue name
# dynamic_scheduler_request_queue
self.request_queue = get_scheduler_request_queue()
# dynamic_scheduler_response_queue
self.response_queue = get_scheduler_response_queue()
for instance_id in range(channel_num):
# 创建channel_num数量的 channel,
# channel name的命名方式: f"dynamic_scheduler_channel_for_{component}_{instance_id}"
channel = self._create_channel(
get_scheduler_channel(self.component_role, instance_id)
)
self.channels.append(channel)
# 可以看到pre_process其实真正的实现在子类的pre_process_impl中
async def pre_process(self, *args, **kwargs):
"""Pre-process. Reset state of ComponentManager and call pre_process_impl."""
self.reset()
await self.pre_process_impl(*args, **kwargs)
async def release_or_allocate(self, train_iter: int) -> tuple[int, int]:
if train_iter == self.n_minibatches - 1:
# 倒数第二轮了,我不做任何实例操作,通知 rollout 把当前任务跑完即可。
await self.main_loop_finalize()
return 0, 0
released_gpu_num = await self.release_resource(train_iter)
incremental_gpu_num = await self.allocate_resource(train_iter)
return (released_gpu_num, incremental_gpu_num)
def update(self, released_instance_num: int = 0, incremental_instance_num: int = 0):
"""更新 ComponentManager 的状态,用于动态调整实例数量和 GPU 分配。
动态调度器会根据负载情况在组件之间迁移 GPU 资源。当一个组件需要释放资源时,
会调用 release 逻辑;当需要获取更多资源时,会调用 allocate 逻辑。
资源分配的基本单位是"实例"(instance),而非单个 GPU。一个实例对应 model_parallel_size 个 GPU。
实例 ID 的分配策略:
- 初始时分配的实例 ID 范围:[0, init_instance_num)
- 后续动态分配的实例 ID 范围:[0, init_instance_num) 被标记为"已释放",
实际可用 ID 从 init_instance_num 开始递增
- current_instance_offset 用于追踪已释放的实例数量,从而计算出下一个可用实例 ID
它就像中线上的游标,左右滑动
实例 ID 示例:
- 初始分配 4 个实例,ID 为 0, 1, 2, 3
- 释放 2 个实例,current_instance_offset = 2,可用 ID 从 4 开始
- 分配 1 个新实例,ID 为 4,current_instance_offset = 1
- 释放 2 个实例,current_instance_offset = 3,可用 ID 从 7 开始
- 以此类推,确保每个实例拥有唯一 ID
Args:
released_instance_num: 要释放的实例数量(非负整数)。
incremental_instance_num: 要新增的实例数量(正整数)。
"""
# 释放和分配互斥,同一次调用只能选择其中一种操作
assert released_instance_num == 0 or incremental_instance_num == 0
if released_instance_num == 0 and incremental_instance_num == 0:
return
if released_instance_num != 0:
# 释放实例:将 GPU 资源从该组件迁出
# 校验:当前实例数必须大于等于要释放的数量
assert self.current_instance_num >= released_instance_num
# 减少当前 GPU 数 = 释放实例数 * 每个实例占用的 GPU 数
self.current_gpu_num -= released_instance_num * self.model_parallel_size
# 减少当前实例数
self.current_instance_num -= released_instance_num
# 记录已释放的实例数(用于后续分配时计算新的实例 ID)
self.current_instance_offset += released_instance_num
else:
# 分配实例:从其他组件获取 GPU 资源
# 校验:新增实例数必须为正
assert incremental_instance_num > 0
# 增加当前实例数
self.current_instance_num += incremental_instance_num
# 重新计算当前 GPU 数(当前实例数 * 每个实例占用的 GPU 数)
self.current_gpu_num = self.current_instance_num * self.model_parallel_size
# 校验:总 GPU 数不能超过集群总 GPU 数量
assert self.current_gpu_num <= self.component_placement._cluster_num_gpus
# 减少待分配的实例计数(已分配了 incremental_instance_num 个实例)
self.current_instance_offset -= incremental_instance_num
3.1 Rollout Manager
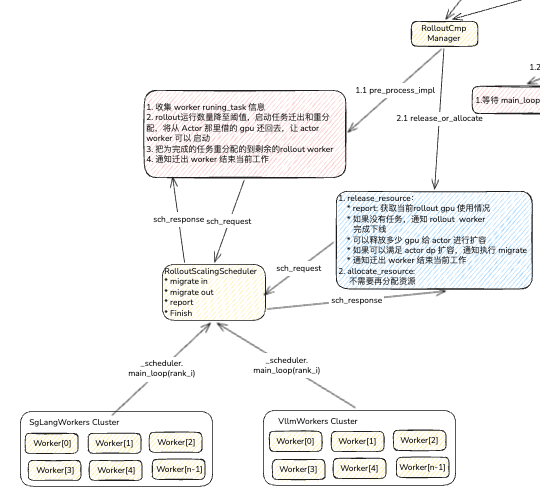
以上可以得知,核心的方法是子类的release_resource和allocate_resource,那么我们分别看一下子类的具体实现
class RolloutManager(ComponentManager):
def __init__(
self,
config: DictConfig,
component_placement: ModelParallelComponentPlacement,
use_pre_process_policy: bool,
use_wait_before_last_iter_policy: bool,
channel_factory: Callable[[str], Channel],
_logger: Logger,
):
"""Initialize the RolloutManager."""
super().__init__(
component_role="rollout",
config=config,
component_placement=component_placement,
use_pre_process_policy=use_pre_process_policy,
use_wait_before_last_iter_policy=use_wait_before_last_iter_policy,
channel_factory=channel_factory,
_logger=_logger,
)
# rollout 创建了rollout个实例的channel,为每个 rollout 实例创建单独的 channel
self.create_channels(self.init_instance_num)
self.max_running_requests = self.cfg.rollout.max_running_requests
self.rollout_total_tasks = (
self.cfg.algorithm.group_size * self.cfg.data.rollout_batch_size
)
async def pre_process_impl(self, running_tasks_threshold: int = -1):
"""Rollout 组件的预处理实现。
Args:
running_tasks_threshold: running_tasks 的阈值。当低于此值时,认为 rollout 阶段基本完成,
可以释放 Actor 资源。默认为 -1,此时使用 rollout_total_tasks // 2。
"""
# 表示 rollout 阶段刚开始,所有任务都在运行
self.running_tasks = self.rollout_total_tasks
# 如果不使用 pre_process_policy(表示静态调度),直接返回,不做任何资源迁移
if not self.use_pre_process_policy:
return
# actor 需要的总资源,actor_world_size 每一轮也会实时更新
migrate_out_gpu_num = self.component_placement.actor_world_size
# 计算需要迁出的总实例
migrate_out_instance_num = migrate_out_gpu_num // self.model_parallel_size
assert migrate_out_gpu_num % self.model_parallel_size == 0
assert migrate_out_instance_num > 0
# 以 50% 为阈值
if running_tasks_threshold == -1:
running_tasks_threshold = self.rollout_total_tasks // 2
assert (
running_tasks_threshold > 0
and running_tasks_threshold < self.rollout_total_tasks
)
while True:
# 观测rollout执行完成情况,获取self.running_tasks,self.total_tasks
# 报告请求发送给RolloutScalingScheduler,并收集目前所有实例使用信息
report_str = await self.report()
# 等待 rollout 的 running_tasks 下降到阈值以下,表明 rollout 阶段即将完成
if (
self.total_tasks == self.rollout_total_tasks
and self.running_tasks <= running_tasks_threshold
):
self._logger.info("npre_process condition satisfied:n" + report_str)
# 触发迁移,释放出GPU,传入需要迁移的实例数
await self.migrate(migrate_out_instance_num)
break
await asyncio.sleep(1)
async def migrate(self, migrate_instance_num: int) -> int:
'''
在动态调度中,当一个 Rollout 实例需要被关闭以释放 GPU 资源时,它正在执行的采样任务会被中断。为了不浪费已经采集到的部分数据,系统会执行以下“迁移”流程:
'''
if migrate_instance_num == 0:
return 0
assert migrate_instance_num < self.current_instance_num
assert len(self.reports) == self.current_instance_num
running_instance_ids = self._get_running_instances()
# 人为切分实例
migrate_out_instance_ids = running_instance_ids[:migrate_instance_num]
# 后半部分的实例,用于完成未完成 rollout 数据,这样就会空出整块的 GPU给 actor 使用了
migrate_in_instance_ids = running_instance_ids[migrate_instance_num:]
'''
# 1. migrate_out (迁出) :
# - 调度器命令即将被关闭的实例执行 Migrate_Out 动作。
# - 这些实例会检查自己手头还有哪些任务没跑完,并将这些任务的信息(特别是 num_aborted )打包成 SeqGroupInfo 对象返回给调度器。
'''
migrate_out_batches = await self.migrate_out(migrate_out_instance_ids)
'''
2. assign_sequences (重新分配) :
- 调度器收集所有从迁出实例返回的 migrate_out_batches 。
- 然后,它会调用 assign_sequences 方法,将这些未完成的任务 重新分配 给那些仍然存活的 Rollout 实例( migrate_in_instance_ids )。
3. migrate_in (迁入) :
- 调度器将这些 batches 打包成 Migrate_In 请求,发送给存活的实例,命令它们“接手”这些被中断的任务。
'''
await self.migrate_in(migrate_in_instance_ids, migrate_out_batches)
# 发送通知,表示migrate_out_instance_ids已迁移完成
await self.finish(RolloutAction.Finish, migrate_out_instance_ids)
return migrate_instance_num * self.model_parallel_size
async def migrate_in(
self,
migrate_in_instance_ids: list[int],
migrate_out_batches: list["SeqGroupInfo"],
):
"""
Args:
migrate_in_instance_ids (List[int]): The list of instance ids to migrate in.
migrate_out_batches (List["SeqGroupInfo"]): The list of migrate out batches.
"""
instance_running_tasks_expected = max(
0, self.running_tasks // len(migrate_in_instance_ids)
)
self._logger.info(
f"[Migrate-Info] "
f"migrate_out_batches_len={len(migrate_out_batches)}, "
f"migrate_out_tasks={sum(batch.num_aborted for batch in migrate_out_batches)}, "
f"{self.running_tasks=}, "
f"{instance_running_tasks_expected=}"
)
migrate_in_instance_reports = [
self.reports[instance_id] for instance_id in migrate_in_instance_ids
]
# 将收到的报告sequence数据,关联到下次运行的 id 实例上。
assigned_batches = self.assign_sequences(
migrate_in_instance_ids,
migrate_in_instance_reports,
migrate_out_batches,
algo="sequential",
)
migrate_in_ids: list[int] = []
migrate_in_requests: list[RolloutScheduleInfo] = []
# 向RolloutScalingScheduler发起重新分配指令
for instance_id, batches in zip(migrate_in_instance_ids, assigned_batches):
if len(batches) > 0:
migrate_in_request = RolloutScheduleInfo(
action=RolloutAction.Migrate_In, data=batches
)
migrate_in_requests.append(migrate_in_request)
migrate_in_ids.append(instance_id)
migrate_out_msg = "[Migrate-Info]:n"
for request, instance_id in zip(migrate_in_requests, migrate_in_ids):
migrate_in_batches: list["SeqGroupInfo"] = request.data
running_tasks = self.reports[instance_id].running_tasks + sum(
batch.num_aborted for batch in migrate_in_batches
)
migrate_out_msg += (
f"rollout-{instance_id} : "
f"migrate_in_batches: {len(request.data)}, "
f"running_tasks={self.reports[instance_id].running_tasks} "
f"-> {running_tasks} ~= {instance_running_tasks_expected}n"
)
self._logger.info(migrate_out_msg)
# 广播至 所有rollout worker,进行迁移动作
await self._scatter_requests(migrate_in_requests, migrate_in_ids)
async def release_resource(
self,
train_iter: int,
) -> int:
"""Release the GPU resources.
Args:
train_iter (int): The current train-iter completed by the actor.
Returns:
int: The number of released GPU resources.
"""
if self.current_instance_num == 0:
return 0
# Report Action
report_str = await self.report()
self._logger.info(report_str)
# Finish Action
if self.running_tasks == 0:
return await self.finish(action=RolloutAction.Finish)
# Wait_For_Finish Action
if (
self.use_wait_before_last_iter_policy
and train_iter == self.n_minibatches - 2
):
return await self.finish(action=RolloutAction.Wait_For_Finish)
# 计算出当前 rollout 最小需要多少实例数,然后根据当前 rollout 实例数计算还能释放多少实例
# 将实例数转化成能释放多少 gpu,然后再观察 actor 如果扩充到多少实例数,当前 gpu 是可以满足的
# 如果满足,released_instance_num为确定的释放的实例数,否则为 0
released_instance_num = self.migrate_policy(train_iter)
# 执行rollout worker 的资源释放
released_gpu_num = await self.migrate(released_instance_num)
return released_gpu_num
# rollout阶段由于是每次step的开始,所以只有release,没有allocate
async def allocate_resource(self, *args, **kwargs) -> int:
"""Allocate the GPU resources.
Returns:
int: The number of incremental GPU resources.
"""
return 0
async def report(self):
"""Check the report of rollout instances."""
alive_instance_ids = self._get_running_instances()
await self._scatter_requests(
RolloutScheduleInfo(action=RolloutAction.Report),
alive_instance_ids,
)
responses = await self._gather_responses(alive_instance_ids)
self.reports = {response.instance_id: response.report for response in responses}
self.total_tasks = sum(report.total_tasks for report in self.reports.values())
self.running_tasks = sum(
report.running_tasks for report in self.reports.values()
)
report_str = f"Rollout Report:ncurrent_total_tasks={self.total_tasks}, current_running_tasks={self.running_tasks}n"
for instance_id, report in self.reports.items():
report_str += f"rollout{instance_id} : total_tasks={report.total_tasks}, running_tasks={report.running_tasks}, completed_tasks={report.completed_tasks}n"
return report_str
L60:在pre_process_impl阶段,RolloutManager会向RolloutScalingScheduler发送信息收集请求,获取所有 rolloutworker 目前的 GPU 使用情况。具体代码 L215,通过发送 request 到每一个订阅的 worker
L68:计算出需要让出多少 gpu 给 actor worker 后,通知 rollout worker 进行任务迁移
L200: 这里是进行 main_loop 过程中release_resource时计算当前rollout 最小规模是,还有多少 GPU 给 actor 集群进行扩容使用,这时需要考虑 actor 扩容到哪个 dp size 的规模能满足 GPU 使用量的。
L201: 再次通知 rollout 进行任务迁移,腾出 gpu
3.2 inference Manager
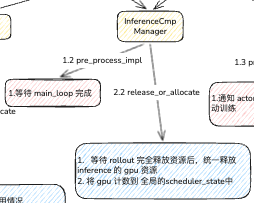
我们再看 inference 的几个 关键方法
class InferenceManager(ComponentManager):
"""Manage resource allocation for inference."""
def __init__(
self,
config: DictConfig,
component_placement: ModelParallelComponentPlacement,
use_pre_process_policy: bool,
use_wait_before_last_iter_policy: bool,
channel_factory: Callable[[str], Channel],
_logger: Logger,
):
"""Initialize the InferenceManager."""
super().__init__(
component_role="inference",
config=config,
component_placement=component_placement,
use_pre_process_policy=use_pre_process_policy,
use_wait_before_last_iter_policy=use_wait_before_last_iter_policy,
channel_factory=channel_factory,
_logger=_logger,
)
self.create_channels(1)
async def wait_for_finish(self) -> int:
"""Last train iter process.
If use_wait_before_last_iter_policy is True, this function will block training until the inference is finished.
"""
while not self.main_loop_finished_handler.done():
await asyncio.sleep(0.1)
released_instance_num = self.current_instance_num
self.update(released_instance_num=released_instance_num)
return released_instance_num * self.model_parallel_size
# pre_process没有实质的预分配工资,只是通过 channel 创建一个 rollout main loop完成的监听
async def pre_process_impl(self):
"""Inference 组件的预处理实现。
Inference 组件的 pre_process 主要是初始化一个异步 handler,用于监听主循环结束的信号。
这个 handler 会在 main_loop_finalize 阶段被 await,确保 inference 组件在所有
训练迭代完成后再进行清理工作。
"""
self.main_loop_finished_handler = self.channels[0].get(
key=self.response_queue, async_op=True
)
async def main_loop_finalize(self):
"""Processing after the last training iteration in main_loop."""
await self.main_loop_finished_handler.async_wait()
assert self.main_loop_finished_handler.done()
# main_loop阶段,reference 和 rollout 是同生命周期的
async def release_resource(
self,
train_iter: int,
) -> int:
"""Release the GPU resources.
Args:
train_iter (int): The current train-iter completed by the actor.
Returns:
int: The number of released GPU resources.
"""
# 当前没有 inference 实例在运行,无需释放。
if self.current_instance_num == 0:
return 0
# 非结尾等待策略:如果 rollout 的 mian loop 完成,自释放自身全部 gpu
if not self.use_wait_before_last_iter_policy:
released_instance_num = (
self.current_instance_num
if self.main_loop_finished_handler.done()
else 0
)
self.update(released_instance_num=released_instance_num)
return released_instance_num * self.model_parallel_size
# Wait for finish
scheduler_state = get_global_scheduer_state()
rollout_current_instance_num = scheduler_state.get_component_instance_num(
"rollout"
)
# 迭代最后2步了 或者 rollout 已经完全释放资源了
need_wait_for_finish = (train_iter == self.n_minibatches - 2) or (
rollout_current_instance_num == 0
)
if need_wait_for_finish:
# 等待 inferfence完成剩余工作,把释放的 gpu 全部更新至self.scheduler_state
return await self.wait_for_finish()
return 0
async def allocate_resource(self, *args, **kwargs) -> int:
"""Allocate the GPU resources.
Returns:
int: The number of incremental GPU resources.
"""
本质上,inference 和 rollout 是共生的,其观察 rollout 的生命周期,一次性的释放自身资源。
3.3 Actor Manager
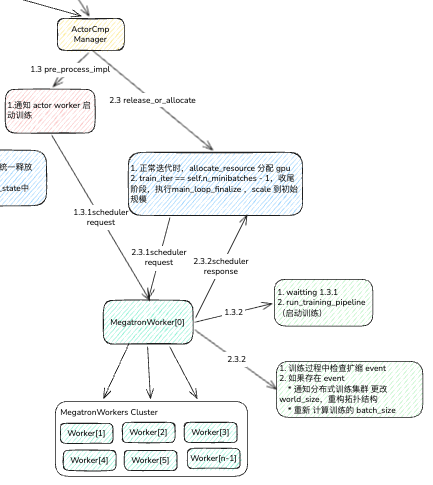
actor manager 整体也不是很复杂,对于 actor 不需要主动释放 GPU,而且逻辑可以在 rollout 进行 GPU 重新分配,因为只有所有actor 都执行完毕,才会进入下一轮 rollout
class ActorManager(ComponentManager):
"""Manage resource allocation for actor."""
def __init__(
self,
config: DictConfig,
component_placement: ModelParallelComponentPlacement,
use_pre_process_policy: bool,
use_wait_before_last_iter_policy: bool,
channel_factory: Callable[[str], Channel],
_logger: Logger,
):
"""Initialize the ActorManager."""
super().__init__(
component_role="actor",
config=config,
component_placement=component_placement,
use_pre_process_policy=use_pre_process_policy,
use_wait_before_last_iter_policy=use_wait_before_last_iter_policy,
channel_factory=channel_factory,
_logger=_logger,
)
self.create_channels(1)
assert hasattr(self, "current_instance_num")
# 到 Actor 的 pre_process 阶段,rollout 已经释放了 gpu 资源了。
# 因此 actor 的 pre_process 只是做 训练的通知就可以了
async def pre_process_impl(self):
if not self.use_pre_process_policy:
return
await (
self.channels[0]
.put(None, key=self.request_queue, async_op=True)
.async_wait()
)
def try_allocate(
self, available_gpu_num: int, actor_valid_dp_sizes: list[int]
) -> int:
# 如果可用 GPU 数量不足以分配一个完整实例,则无法分配
if available_gpu_num < self.model_parallel_size:
return 0
incremental_gpu_num = 0
# 确保当前实例数是合法档位之一,且尚未达到最大档位(否则无需分配)
assert (
self.current_instance_num in actor_valid_dp_sizes
and self.current_instance_num != actor_valid_dp_sizes[-1]
)
# 找到当前实例数在合法档位(dp size)列表中的索引
index = actor_valid_dp_sizes.index(self.current_instance_num)
# 从当前档位的下一个开始,逐个尝试更大的档位
for next_dp_size in actor_valid_dp_sizes[index + 1 :]:
# 计算从当前实例数扩容到 next_dp_size 所需的 GPU 数量
needed_gpu_nums = (
next_dp_size - self.current_instance_num
) * self.model_parallel_size
if needed_gpu_nums <= available_gpu_num:
# 可用资源足够,记录该增量(贪心:尽可能多分配)
incremental_gpu_num = needed_gpu_nums
else:
break
# 最终分配的增量不应超过可用资源
assert incremental_gpu_num <= available_gpu_num
return incremental_gpu_num
# train_iter == self.n_minibatches - 1时触发
async def scale(self, new_gpu_num: int):
"""Send scale info to actor."""
# 满足需求,不需要进行扩缩
scale_info = {"world_size": new_gpu_num}
if new_gpu_num == self.current_gpu_num:
scale_info = None
# 通过 channel 异步发送 scale_info 给 Actor worker[0]
await (
self.channels[0]
.put(
scale_info,
key=self.request_queue,
async_op=True,
)
.async_wait()
)
if new_gpu_num > self.current_gpu_num:
incremental_instance_num = (
new_gpu_num // self.model_parallel_size - self.current_instance_num
)
self.update(incremental_instance_num=incremental_instance_num)
elif new_gpu_num < self.current_gpu_num:
released_instance_num = (
self.current_instance_num - new_gpu_num // self.model_parallel_size
)
self.update(released_instance_num=released_instance_num)
async def allocate_resource(
self,
train_iter: int,
) -> int:
"""Allocate the GPU resources.
Based on the value of available_gpu_num, try to allocate resources.
If the allocation result shows that the new_gpu_num != self.current_gpu_num, then send {"world_size": new_gpu_num} to actor, else send None.
Args:
train_iter (int): The current train-iter completed by the actor.
Returns:
incremental_gpu_num (int): The number of incremental GPU resources of actor.
"""
scheduler_state = get_global_scheduer_state()
available_gpu_num = scheduler_state.available_gpu_num
actor_valid_dp_sizes = scheduler_state.actor_valid_dp_sizes
# 从目前可以获得的 gpu 数量,计算最大扩容可能会用到多少 gpu
incremental_gpu_num = self.try_allocate(available_gpu_num, actor_valid_dp_sizes)
assert incremental_gpu_num >= 0
# 扩缩至目标大小数量的 worker
await self.scale(incremental_gpu_num + self.current_gpu_num)
return incremental_gpu_num
# 这个是确认训练完成的方法,在 SchedulerWorker 中main_loop 开始阶段进行调用检查
async def wait_for_actor_update(self):
"""Wait for the actor update."""
await self.channels[0].get(key=self.response_queue, async_op=True).async_wait()
# actor在self.n_minibatches的正常阶段不需要释放 gpu 资源。
# 只有train_iter == self.n_minibatches - 1时,会调用main_loop_finalize进行资源的释放
async def release_resource(self, *args, **kwargs) -> int:
return 0
async def main_loop_finalize(self):
"""Processing after the last training iteration in main_loop. GPU resources of actor should be scale-down to init_gpu_num."""
return await self.scale(self.init_gpu_num)
L29:在 pre_process 阶段,通知 actor woker 开始训练
L100:allocate_resource和release_resource阶段:
- allocate_resource会根据目前全局 gpu 的数量评估能扩充到多大规模,然后执行 scale
- release_resource功能由main_loop_finalize(L136)在最后一步迭代代替,将 actor 规模扩缩到 init_instance大小
L79: 这里是重点注意部分,当调用 scale 时,manager 会将目标扩缩请求发送 actor worker[0], 其scheduler_scale_sync方法会拿到目前需要扩缩的 world_size,然后让 trainer 进行MP 的重新分配,同时 batch_size 也会重新计算分配
4. 总结
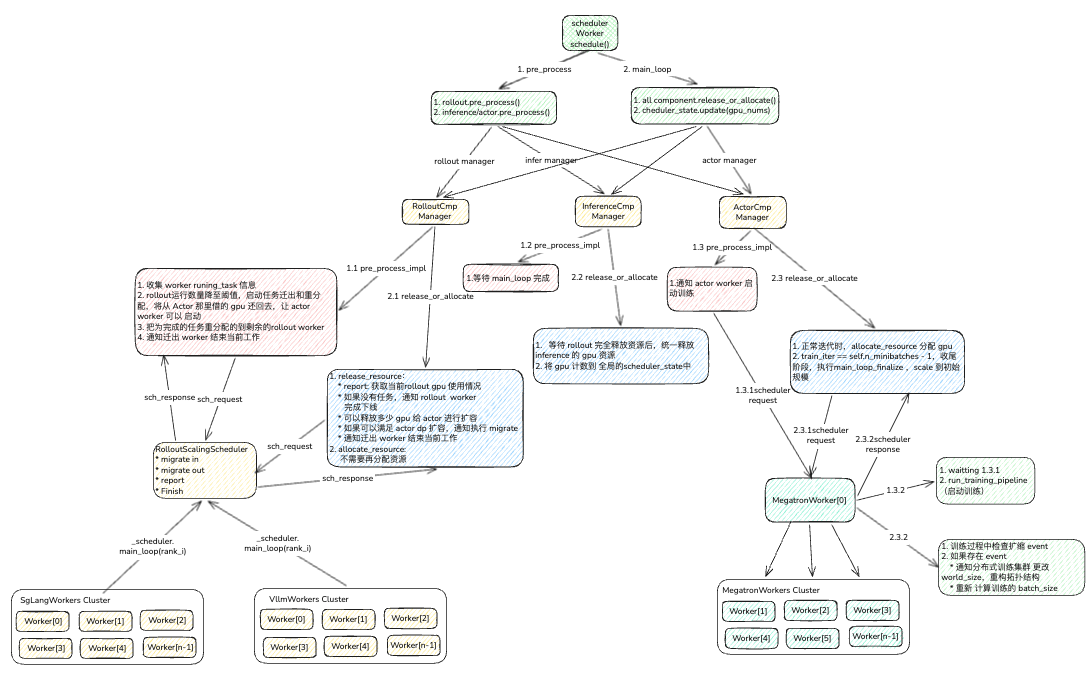
根据以上代码,我们再 review 一下总体逻辑:
- scheduler worker 由 runner 持有,在 LR loop 中,通过调用 schedule()方法,执行 pre_process 和 main_loop 两个主要阶段。
- pre_process阶段:以 rollout 为主要调节点,这个阶段需要根据全局 gpu 可用资源,rollout + inferfence占用目前可使用的所有 gpu 开始执行,当降至 50% 阈值时,触发 gpu 释放流程,并通知 actor 进行训练。
-
main_loop阶段: rollout继续进行任务重新排布计算,计算并更新 rollout最小的实例数,然后将缩减空余的 gpu 通知 actor 进行使用。
在训练过程中,实时进行可用的 gpu 扩容分配;在train_iter == self.n_minibatches - 1倒数第二轮的训练时,actor 会根据做训练结束准备,并将 worker 规模设定至init_gpu_num